Building scalable multi-tenant applications in Go

Prepared for and presented at GopherCon Israel 2025.
Introduction
In this post, we will explore different strategies for building scalable multi-tenant applications in Go based on our experience building the backend for Atlas Cloud, which is part of our commercial offering.
But first, let's clarify what we mean by multi-tenant applications.
Multi-tenancy is a property of a system where a single instance serves multiple customers (tenants).
As a commercial enterprise, your goal is, of course, to have lots of customers! But while you want to serve many customers, they expect a smooth and seamless experience, as if they were the only ones using your service.
Two important promises you implicitly make to your customers are:
- Data Isolation: Each tenant's data is isolated and secure, ensuring that one tenant cannot access another's data.
- Performance: The application should perform well regardless of the number of tenants, ensuring that one tenant's usage does not degrade the experience for others.
Let's explore some ways in which we might fulfill these promises.
Physical Isolation
The most straightforward way to ensure data and performance isolation is to run a separate instance of the application for each tenant. This approach is often referred to as "physical isolation" or "dedicated instances."
By running a separate instance for each tenant, you ensure that:
- Each tenant's data is stored in a separate database, guaranteeing complete isolation. If needed, tenants can run in different VPCs or even separate cloud accounts.
- Tenants consume resources independently, so one tenant's usage does not affect others, thereby eliminating the "noisy neighbor" problem.
However, most companies do not go this route for several reasons:
- Operational Overhead: Deploying your app to hundreds or thousands of production environments, each with its own database and configuration, can be very complex to manage.
- Cost: If your company is going to be paying the cloud provider for each tenant's resources, the cost can quickly become prohibitive.
- Scalability: If adding a new tenant requires deploying a new instance, scaling the application to support many tenants can become a bottleneck.
- Visibility: Monitoring and debugging issues across many instances can be challenging, as you need to aggregate logs and metrics from all instances.
Logical Isolation
An alternative approach is to run a single instance of the application that serves multiple tenants, often referred to as "logical isolation." In this model, tenants share the same application code and database, but their data is logically separated. Logical isolation can be summarized as:
Shared infrastructure, scoped requests
Let's see how this might look like in practice in a Go application, starting with a simple GORM example:
package main
type Tenant struct {
ID uint `gorm:"primaryKey" json:"id"`
Name string `json:"name"`
}
type Customer struct {
ID uint `gorm:"primaryKey" json:"id"`
Name string `json:"name"`
TenantID uint `json:"tenant_id"`
}
In this example, we have two models: Tenant and Customer. Each Customer belongs to a Tenant, and the TenantID
field in the Customer model is used to associate each customer with a specific tenant.
To ensure data isolation, we must scope the queries to the tenant's ID in each request. For example, when fetching customers, we would do something like this:
func (s *Server) customersHandler(w http.ResponseWriter, r *http.Request) {
tid, err := s.getTenantID(r)
if err != nil {
w.WriteHeader(http.StatusBadRequest)
w.Write([]byte("invalid tenant"))
return
}
var customers []Customer
if err := s.db.
Where("tenant_id = ?", tid).
Find(&customers).Error; err != nil {
w.WriteHeader(http.StatusInternalServerError)
return
}
json.NewEncoder(w).Encode(customers)
}
Notice how we fetch the tenant ID from the request context and use it to scope the query to the tenant's data.
This approach has many advantages over physical isolation:
- Operational Simplicity: You only need to deploy and manage a single instance of the application, which simplifies deployment and operations.
- Cost Efficiency: You can serve many tenants with a single instance, reducing the cost of running the application.
- Scalability: You can scale the application horizontally by adding more instances and handle more tenants without needing to deploy new instances for each tenant.
- Visibility: You can aggregate logs and metrics from a single instance, making it easier to monitor and debug issues.
However, let's consider some of the downsides of this approach.
Suppose you want to add an endpoint that returns a report for a specific tenant. You might implement it like this:
type OrderSumResult struct {
CustomerID uint `json:"customer_id"`
Customer string `json:"customer"`
OrderCount int `json:"order_count"`
}
func (s *Server) orderSumsHandler(w http.ResponseWriter, r *http.Request) {
tid, err := s.getTenantID(r)
if err != nil {
w.WriteHeader(http.StatusUnauthorized)
w.Write([]byte("unauthenticated"))
return
}
var results []OrderSumResult
err = s.db.Raw(`
SELECT c.id as customer_id, c.name as customer, COUNT(o.id) as order_count
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id AND o.tenant_id = c.tenant_id
WHERE c.tenant_id = ?
GROUP BY c.id, c.name
`, tid).Scan(&results).Error
if err != nil {
w.WriteHeader(http.StatusInternalServerError)
w.Write([]byte("query error"))
return
}
json.NewEncoder(w).Encode(results)
}
When your endpoints are simple CRUD operations, it's fairly straightforward to scope the queries to the tenant's ID. However, as your application grows and you start adding more complex queries, you may find that scoping the queries to the tenant's ID becomes more challenging. Custom SQL needs to be carefully crafted and reviewed to ensure that the tenant's data is always isolated.
In other words, tenancy becomes a constant concern for any developer working on the codebase, and if your team is large and ships a lot of code, mistakes will happen.
This combination of easy to get wrong and high impact is something that any architect should avoid. In such cases, it is advisable to find ways to push the concern of tenancy to the app infrastructure layer, so that developers do not need to think about it in their day-to-day work.
Strategies for Multi-Tenancy in Go
When building the SaaS side of Atlas, we looked for ways to handle multi-tenancy that would let us scale, isolate data, and remain fast without making life harder for developers. We asked ourselves:
Can we harness logical isolation while maintaining a "single-tenant" developer experience?
In the remainder of this post, I will demonstrate three approaches that you can consider to achieve this goal:
- ORM Middleware: Pushing the decision of tenancy to a shared middleware layer on the ORM level.
- Row-Level Security (RLS): If you're running on PostgreSQL, you can use RLS to enforce tenancy at the database level.
- Schema-per-Tenant: A less-known approach that uses middleware to create scoped database connections for each request, allowing you to use a separate schema for each tenant.
Using Ent Privacy Rules
Ent is a popular Go ORM that provides a powerful way to define your data model and generate type-safe code for working with your database. Ent was created by Ariel, my co-founder, while he was at Facebook, and has since become part of the Linux Foundation.
Similar to Atlas, Ent is based on the concept of "schema as code", where you define your data model in Go code, and Ent's code generation engine takes things from there. Ent supports many useful features such as:
- Graph modeling of your data (nodes and edges)
- Easy traversal of your data model
- Code generation for type-safe queries
- Automatically generated GraphQL, REST, and gRPC APIs
Ent also has a powerful privacy rules feature that allows you to define rules for accessing your data based on the context of the request. As the Ent docs say:
The main advantage of the privacy layer is that you write the privacy policy once (in the schema) and it is always evaluated. No matter where queries and mutations are performed in your codebase, it will always go through the privacy layer.
Let's see how we can use Ent's privacy rules in tandem with some fun Go tricks to enforce tenancy in our application.
Step 1: Injecting the Tenant ID into the Context
To enforce tenancy, we need to inject the tenant ID into the context of each request. This can be done using a middleware that extracts the tenant ID from the request and adds it to the context. Here's an example of how to do this:
package viewer
type middleware struct {
*ent.Client
}
func Middleware(c *ent.Client) func(http.Handler) http.Handler {
m := &middleware{c}
return m.handle
}
func (m *middleware) handle(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, req *http.Request) {
tenant, err := m.tenant(req)
if err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
req = req.WithContext(
NewContext(
req.Context(),
UserViewer{T: tenant},
),
)
next.ServeHTTP(w, req)
})
}
func (m *middleware) tenant(r *http.Request) (*ent.Tenant, error) {
tid := r.Header.Get(Header)
if tid == "" {
return nil, http.ErrNoLocation
}
id, err := strconv.Atoi(tid)
if err != nil {
return nil, err
}
return m.Tenant.Get(r.Context(), id)
}
In this example, we define a middleware that extracts the tenant ID from the request header and adds it to the context
using a custom UserViewer type. The tenant method retrieves the tenant from the database using the tenant ID and
then uses it to create a new context with the tenant information.
Next, we need to register this middleware in our HTTP server:
// NewServer creates a new HTTP server with ent client and returns http.Handler
func NewServer(client *ent.Client) http.Handler {
s := &Server{client: client}
r := chi.NewRouter()
r.Use(middleware.Recoverer)
r.Use(viewer.Middleware(client))
r.Get("/customers", s.GetCustomers)
r.Get("/products", s.GetProducts)
r.Get("/orders", s.GetOrders)
r.Get("/order-sums", s.orderSumsHandler)
return r
}
By using the viewer.Middleware, we ensure that the tenant ID is injected into the context of each request, allowing us
to access it later in our handlers.
Step 2: Defining the data model
Before we get into the actual privacy rules, let's define our data model using Ent. We'll create two entities: Tenant
and Customer:
package schema
import (
"entgo.io/ent"
"entgo.io/ent/schema/edge"
"entgo.io/ent/schema/field"
)
// Tenant holds the schema definition for the Tenant entity.
type Tenant struct {
ent.Schema
}
// Fields of the Tenant.
func (Tenant) Fields() []ent.Field {
return []ent.Field{
field.String("name").Unique(),
}
}
// Edges of the Tenant.
func (Tenant) Edges() []ent.Edge {
return []ent.Edge{
edge.To("customers", Customer.Type),
}
}
This schema defines a Tenant entity with a unique name and an edge to the Customer entity. Now let's define the Customer entity:
package schema
import (
"entgo.io/ent"
"entgo.io/ent/schema/edge"
"entgo.io/ent/schema/field"
)
// Customer holds the schema definition for the Customer entity.
type Customer struct {
ent.Schema
}
func (Customer) Fields() []ent.Field {
return []ent.Field{
field.String("name"),
}
}
func (Customer) Edges() []ent.Edge {
return []ent.Edge{
edge.To("orders", Order.Type),
}
}
func (Customer) Mixin() []ent.Mixin {
return []ent.Mixin{TenantMixin{}}
}
Notice that we use a TenantMixin to apply the tenancy logic to the Customer entity. Because each and every entity
in our application will be scoped to a tenant, we can define a mixin that applies the tenancy logic to all entities.
Let's define the TenantMixin:
package schema
import (
"entgo.io/ent"
"entgo.io/ent/schema/edge"
"entgo.io/ent/schema/field"
"entgo.io/ent/schema/mixin"
"gophercon/entpriv/ent/rule"
)
// TenantMixin for embedding the tenant info in different schemas.
type TenantMixin struct {
mixin.Schema
}
// Fields for all schemas that embed TenantMixin.
func (TenantMixin) Fields() []ent.Field {
return []ent.Field{
field.Int("tenant_id").
Immutable(),
}
}
// Edges for all schemas that embed TenantMixin.
func (TenantMixin) Edges() []ent.Edge {
return []ent.Edge{
edge.To("tenant", Tenant.Type).
Field("tenant_id").
Unique().
Required().
Immutable(),
}
}
func (TenantMixin) Policy() ent.Policy {
return rule.FilterTenantRule()
}
TenantMixin defines a tenant_id field that is immutable and required, and an edge to the Tenant entity.
The Policy method returns a custom policy that we will define next, which will enforce the tenancy logic.
Step 3: Defining the Privacy Rule
Next, we need to define the privacy rule that will enforce the tenancy logic. We can do this by implementing a custom privacy rule that filters the data based on the tenant ID in the context. Here's how we can do that:
package rule
import (
"context"
"entgo.io/ent/entql"
"gophercon/entpriv/ent/privacy"
"gophercon/entpriv/viewer"
)
// FilterTenantRule is a query/mutation rule that filters out entities that are not in the tenant.
func FilterTenantRule() privacy.QueryMutationRule {
// TenantsFilter is an interface to wrap WhereHasTenantWith()
// predicate that is used by both `Group` and `User` schemas.
type TenantsFilter interface {
WhereTenantID(entql.IntP)
}
return privacy.FilterFunc(func(ctx context.Context, f privacy.Filter) error {
view := viewer.FromContext(ctx)
tid, ok := view.Tenant()
if !ok {
return privacy.Denyf("missing tenant information in viewer")
}
tf, ok := f.(TenantsFilter)
if !ok {
return privacy.Denyf("unexpected filter type %T", f)
}
// Make sure that a tenant reads only entities that have an edge to it.
tf.WhereTenantID(entql.IntEQ(tid))
// Skip to the next privacy rule (equivalent to return nil).
return privacy.Skip
})
}
In this example, we define a FilterTenantRule that checks the tenant ID in the context and filters the data based on it.
The TenantsFilter interface is used to wrap the WhereTenantID predicate that is used by the Customer entity as well
as any other entity that embeds the TenantMixin. This provides a type-safe way to filter the data based on the tenant ID.
Step 4: Write single-tenant code
Now, we can write our application code as if it were single-tenant, without worrying about the tenancy logic. For example, we can write a handler to get customers for the tenant:
// GetCustomers handles GET /customers request
func (s *Server) GetCustomers(w http.ResponseWriter, r *http.Request) {
customers, err := s.client.Customer.Query().All(r.Context())
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/json")
json.NewEncoder(w).Encode(customers)
}
Notice that this code has no tenancy logic in it. The Customer.Query().All(r.Context()) call will automatically
filter the customers based on the tenant ID in the context thanks to the privacy rule we defined earlier.
To summarize, here's the journey of a request in our application:

This approach allows us to write single-tenant code while leveraging Ent's privacy rules to enforce tenancy at the ORM level.
However, this approach has a few important limitations:
- Custom queries. If you need to "break the glass" and write custom SQL queries that do not use the Ent query builder, you will need to manually scope the queries to the tenant's ID, which can lead to mistakes.
- Other clients. If you have other clients that access the database directly (e.g., a reporting service or a data export tool), you will need to ensure that they also respect the tenancy logic, which means re-implementing the same logic in those clients.
- Noisy neighbors. Since all tenants share the same database and app, this approach does not provide any help with performance isolation. If one tenant has a heavy load, it can affect the performance of other tenants.
Row-Level Security (RLS)
If you're using PostgreSQL, you can leverage its built-in Row-Level Security (RLS) feature to enforce tenancy at the database level. Row-Level Security allows you to define policies that control which rows are visible to which users, based on the context of the request.
Using RLS, we can overcome some of the limitations that are imposed by solving multi-tenancy at the ORM level. To enable RLS for a table, you can use the following SQL command:
--- Enable row-level security on the users table.
ALTER TABLE "customers" ENABLE ROW LEVEL SECURITY;
-- Create a policy that restricts access to
-- rows in the users table based on the current tenant.
CREATE POLICY tenant_isolation ON "users"
USING (
"tenant_id" = current_setting('app.current_tenant')::integer
);
Then, you can set the app.current_tenant setting in the context of each request, and PostgreSQL will automatically
filter the rows based on the tenant ID. For example with Ent:
ctx := sql.WithIntVar(
ctx, "app.current_tenant",
tenant1.ID,
)
// Get only tenant1 customers
users := client.Customer.Query().AllX(ctx)
Filtering the rows at the database level has many advantages:
- Performance: RLS policies are executed at the database level, which can be more efficient than filtering the data at the application level.
- Security: RLS policies are enforced by the database, which means that even if you have other clients that access the database directly, they will still respect the tenancy logic.
- Simplicity: You can write your application code as if it were single-tenant, without worrying about the tenancy logic.
However, RLS also has some limitations:
- Database-specific: RLS is a PostgreSQL-specific feature, so if you switch to a different database, you will need to re-implement the tenancy logic.
- Requires careful schema management: You need to ensure that the RLS policies are applied to all relevant tables, which can be challenging if you have a large schema or many tables. To help with this, you can use Atlas to manage RLS policies and enforce their existence using Atlas's custom schema rules feature.
- Noisy neighbors: Similar to the Ent privacy rules approach, RLS does not provide any help with performance isolation. If one tenant has a heavy load, it can affect the performance of other tenants.
To learn about how to use Atlas to manage RLS policies, check out this blogpost.
Schema per Tenant
The approach we ended up using for Atlas's SaaS system is a less common one, but it has proven to be very effective for our use case. It combines the benefits of logical isolation with the simplicity of single-tenant code, while also providing pretty good isolation. This approach is often referred to as "schema-per-tenant" or "database-per-tenant."
With schema-per-tenant, we use a single database instance, but each tenant has its own schema within that database (tables are replicated across schemas). This allows us to isolate each tenant's data while still keeping costs low.
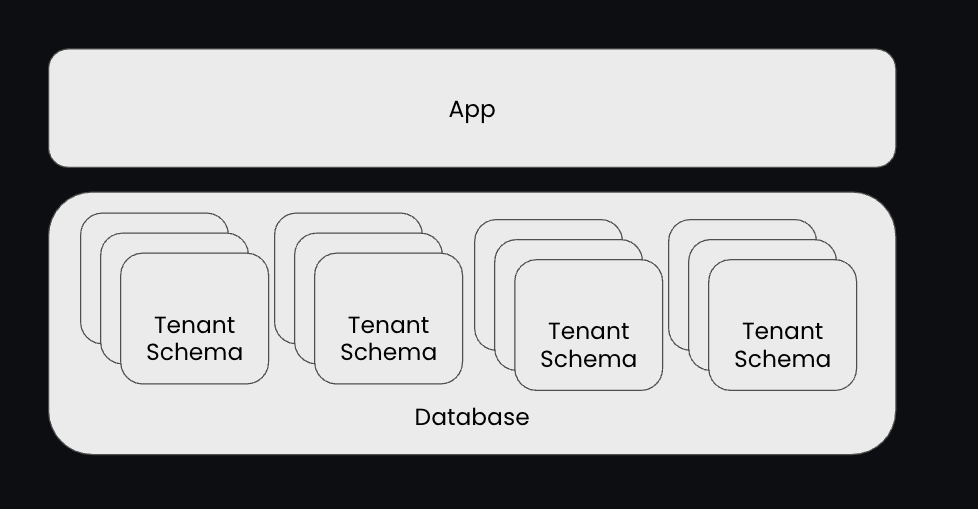
Request scoping is done at the middleware level, where we create a scoped database client for each tenant based on the tenant ID in the request context.
The middleware handler looks like this:
type middleware struct {
url *url.URL
dialect string
clients map[string]*ent.Client
sync.Mutex
}
func (m *middleware) handle(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, req *http.Request) {
client, err := m.tenantClient(req)
if err != nil {
http.Error(w, err.Error(), http.StatusBadRequest)
return
}
ctx := ent.NewContext(req.Context(), client)
next.ServeHTTP(w, req.WithContext(ctx))
})
}
func (m *middleware) tenantClient(r *http.Request) (*ent.Client, error) {
m.Lock()
defer m.Unlock()
name := r.Header.Get(Header)
if name == "" {
return nil, fmt.Errorf("missing tenant ID")
}
client, ok := m.clients[name]
if !ok {
return ent.Open(m.dialect, m.urlFor(name))
}
return client, nil
}
func (m *middleware) urlFor(t string) string {
u := *m.url
q := u.Query()
q.Set("search_path", t)
u.RawQuery = q.Encode()
return u.String()
}
When a request comes in, the middleware extracts the tenant ID from the request header and uses it to create a
scoped database client for that tenant. The urlFor method modifies the database URL to set the search_path to the
tenant's schema, which allows us to use the same database connection for all tenants while isolating their data.
We use sync.Mutex to ensure that the clients map is thread-safe, as multiple requests can come in concurrently.
This approach has several advantages:
- Single-tenant developer experience: Developers can write single-tenant code without worrying about tenancy logic, as the middleware handles the scoping of requests.
- Psuedo physical isolation: Each tenant's data is isolated in its own schema, which provides a good level of isolation while still keeping costs low. We rely on the database to enforce data isolation, so we don't need to worry about accidentally leaking data between tenants.
- Private DB instances: If needed, we can easily switch to a physical isolation model by creating a separate database instance for each tenant, as the middleware can be adapted to handle that case as well. In these cases we can allocate dedicated resources for important tenants, thereby protecting the from noisy neighbors.
- VPC peering: If needed, we can also run each tenant in a separate VPC or cloud account, as the middleware can be adapted to handle that case as well.
Why not use schema-per-tenant everywhere?
If you search for database or schema-per-tenant online, you will quickly find that this approach is disliked by many. To the point where one engineer wrote this:
"This architecture decisions is one of my biggest regrets, and we are currently in the process of rebuilding into a single database model."
The downsides of this approach are mostly around the challenge of managing so many schemas in a single database:
- Migration duration scales linearly. When you need to run a migration, it needs to be applied to all schemas. This can lead to long migration times, especially if you have many tenants.
- Detecting and fixing inconsistencies is hard. Eventually, some schemas may diverge from the others, leading to inconsistencies that are hard to detect and fix. This becomes a nasty needle in a haystack problem.
- Rollbacks are difficult. If you need to roll back a migration, you need to roll it back for all schemas, which can be difficult to manage and can lead to downtime for tenants.
To solve these issues, we have baked in support for schema-per-tenant into Atlas (almost from the start). Atlas provides a way to define "target groups" that allow you to run migrations on a subset of schemas, which can help with managing a large number of schemas. For example:
data "sql" "tenants" {
url = var.url
query = <<EOS
SELECT `schema_name`
FROM `information_schema`.`schemata`
WHERE `schema_name` LIKE ?
EOS
args = [local.pattern]
}
env "prod" {
for_each = toset(data.sql.tenants.values)
url = urlsetpath(var.url, each.value)
}
In this example we define a data source that queries the information_schema to get a list of all schemas that match a
certain pattern. We then use this data source to create an environment for each schema, which allows us to run migrations
on a subset of schemas. This way, we can run migrations on all schemas that match the pattern, without having to
manually define each schema in the Atlas configuration.
With the proper tooling in place, schema-per-tenant can be a very effective way to manage multi-tenancy in Go applications.
To learn more about how to use Atlas with schema or database per tenant, check out our dedicated guide.
Conclusion
In this post, we explored different strategies for building scalable multi-tenant applications in Go based on our experience building the backend for Atlas Cloud. We discussed the challenges of multi-tenancy and how to overcome them by leveraging logical isolation, ORM middleware, Row-Level Security, and schema-per-tenant. Here are my key takeaways:
- Physical Isolation where you must. Some customers will require physical isolation for compliance or security reasons, these are usually large enterprises that can pay for it which makes it a great problem to have!
- Beware of data leaks with logical isolation. When using logical isolation, be careful to ensure that data is always scoped to the tenant's ID. This can be done on every request, manually, but can be error-prone.
- Push tricky stuff to infrastructure. When we encounter an issue that is both easy to get wrong and has a high impact, we should try to push it to the infrastructure layer so developers do not need to worry about it in their day-to-day work.
- Schema-per-tenant is great if you have good tools. While less common, schema-per-tenant can be a very effective way to manage multi-tenancy in Go applications, especially if you have the right tools to manage it. Atlas provides a way to define target groups that allow you to run migrations on a subset of schemas, which can help with managing a large number of schemas.
I had a great time presenting this talk at GopherCon, and I hope you found it useful. If you have any questions or comments, feel free to reach out to us our Discord server.