The Hard Truth about GitOps and Database Rollbacks

Prepared for KubeCon North America 2024
Introduction
For two decades now, the common practice for handling rollbacks of database schema migrations has been pre-planned "down migration scripts". A closer examination of this widely accepted truth reveals critical gaps that result in teams relying on risky, manual operations to roll back schema migrations in times of crisis.
In this post, we show why our existing tools and practices cannot deliver on the GitOps promise of "declarative" and "continuously reconciled" workflows and how we can use the Operator Pattern to build a new solution for robust and safe schema rollbacks.
The Undo Button
One of the most liberating aspects of working on digital products is the ability to roll back changes. The Undo Button, I would argue, is one of the most transformative features of modern computing.
Correcting mistakes on typewriters was arduous. You would roll the carriage back and type over any errors, leaving messy, visible corrections. For bigger changes, entire pages had to be retyped. Correction fluid like whiteout offered a temporary fix, but it was slow and imprecise, requiring careful application and drying time.
Digital tools changed everything. The Undo Button turned corrections into a simple keystroke, freeing creators to experiment without fear of permanent mistakes. This shift replaced the stress of perfection with the freedom to try, fail, and refine ideas.
Rollbacks and Software Delivery
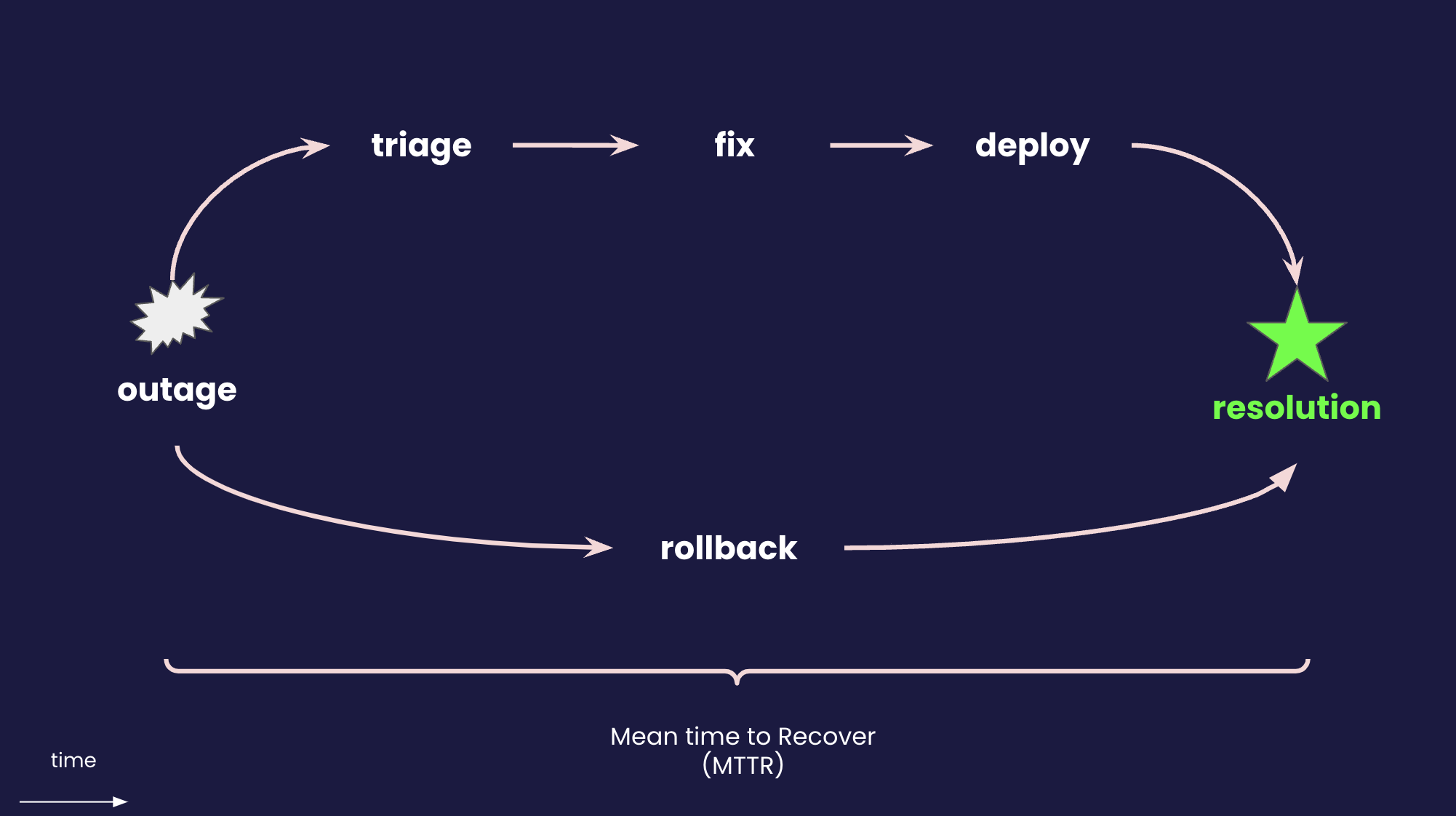
When it comes to software delivery, having an Undo Button is essential as well. The ability to roll back changes to a previous state is a critical safety net for teams deploying new features, updates, or bug fixes. Specifically, rollbacks impact one of the key metrics of software delivery: Mean Time to Recovery (MTTR).
MTTR is a measure of how quickly a system can recover from failures. When a deployment fails, or a bug is discovered in production, teams generally have two options: triage and fix the issue (roll forward), or roll back to a previous known stable state.
When the fix to an issue is not immediately clear, or the issue is severe, rolling back is often the fastest way to restore service. This is why having a reliable rollback mechanism is crucial for reducing MTTR and ensuring high availability of services.
How are rollbacks even possible?
Undoing a change in a local environment like a word processor is straightforward. There are multiple ways to implement an Undo Button, but they all rely on the same basic principle: the system keeps track of every change made and can revert to a previous state.
In a distributed system like modern, cloud-native applications, things are not so simple. Changes are made across multiple components with complex dependencies and configurations.
The key capability that enables rolling back changes is described in the seminal book, "Accelerate: The Science of Lean Software and DevOps". The authors identify "Comprehensive Configuration Management" as one of the key technical practices that enables high performance in software delivery:
"It should be possible to provision our environments and build, test, and deploy our software in a fully automated fashion purely from information stored in version control.” 1
In theory, this means that if we can store everything there is to know about our system in version control, and have an automated way to apply these changes, we should be able to roll back to a previous state by simply applying a previous commit.
GitOps and Rollbacks
The principle of "Comprehensive Configuration Management" evolved over the years into ideas like "Infrastructure as Code" and "GitOps". These practices advocate for storing all configuration and infrastructure definitions in version control in a declarative format, and using automation to apply these changes to the system.
Projects like ArgoCD and Flux have popularized the GitOps approach to managing Kubernetes clusters. By providing a structured way to define the desired state of your system in Git (e.g., Kubernetes manifests), and automatically reconciling the actual state with it, GitOps tools provide a structured and standardized way to manage satisfy this principle.
On paper, GitOps has finally brought us a working solution for rollbacks. Revert the commit that introduced the issue, and all of your problems are gone!
Problem solved. End of talk. Right?
The Hard Truth
Teams that have tried to fully commit to the GitOps philosophy usually find that the promise of "declarative" and "continuously reconciled" workflows is not as straightforward as it seems. Let's consider why.
Declarative resource management works exceptionally well for stateless resources like containers. The way Kubernetes handles deployments, services, and other resources is a perfect fit for GitOps. Consider how a typical deployment rollout works:
- A new replica set is created with the new version of the application.
- Health checks are performed to ensure the new version is healthy.
- Traffic is gradually shifted to healthy instances of the new version.
- As the new version proves stable, the old version is scaled down and eventually removed.
But will this work for stateful resources like databases? Suppose we want to change the schema of a database. Could we apply the same principles to roll back a schema migration? Here's what it would look like:
- A new database is spun up with the new schema.
- Health checks are performed to ensure the new schema is healthy.
- Traffic is gradually shifted to the new database instance.
- The old database is removed.
This would get the job done... but you would probably find yourself out of a job soon after.
Stateless resources are really great to manage because we can always throw out whatever isn't working for us and start fresh. But databases are different. They are stateful, and they are comprised not only of a software component (the database engine), the configuration (server parameters and schema), but also the data itself. The data itself cannot, by definition, be provisioned from version control.
Stateful resources like databases require a different approach to manage changes.
Up and Down Migrations
The common practice for managing schema changes in databases is to use "up" and "down" migration scripts in tandem with a migration tool (like Flyway or Liquibase). The idea is simple: when you want to make a change to the schema, you write a script that describes how to apply the change (the "up" migration). Additionally, you write a script that describes how to undo the change (the "down" migration).
For example, suppose you wanted to add a column named "short_bio" to a table named "users". Your up migration script might look like this:
ALTER TABLE users
ADD COLUMN short_bio TEXT;
And your down migration script might look like this:
ALTER TABLE users DROP COLUMN short_bio;
In theory, this concept is sound and satisfies the requirements of "Comprehensive Configuration Management". All information needed to apply and roll back the change is stored in version control.
Theory, once again, is quite different from practice.
The Myth of Down Migrations

After interviewing hundreds of engineers on this topic, we found that despite being a widely accepted concept, down are rarely used in practice. Why?
Naive assumptions
When you write a down migration, you are essentially writing a script that will be executed in the future to revert the changes you are about to make. By definition, this script is written before the "up" changes are applied. This means that the down migration is based on the assumption that the changes will be applied correctly.
But what if they are not?
Suppose the "up" migration was supposed to add two columns, the down file would be written to remove these two columns. But what if the migration was partially applied and only one column was added? Running the down file would fail, and we would be stuck in an unknown state.
Yes, some databases like PostgreSQL support transactional DDL, which means that if the migration fails, the changes are rolled back, and you end up with a state this consistent with a specific revision. But even for PostgreSQL, some operations cannot be run in a transaction, and the database can end up in an inconsistent state.
For MySQL, which does not support transactional DDL, the situation is even worse. If a migration fails halfway through, you are left with only a partially applied migration and no way to roll back.
Data loss
When you are working on a local database, without real traffic, having the up/down mechanism for migrations might feel like hitting Undo and Redo in your favorite text editor. But in a real environment with real traffic, it is not the case.
If you successfully rolled out a migration that added a column to a table, and then decided to revert it, its inverse
operation (DROP COLUMN) does not merely remove the column. It deletes all the data in that column. Re-applying the
migration would not bring back the data, as it was lost when the column was dropped.
For this reason, teams that want to temporarily deploy a previous version of the application, usually do not revert the database changes, because doing so will result in data loss for their users. Instead, they need to assess the situation on the ground and figure out some other way to handle the situation.
Incompatibility with modern deployment practices
Many modern deployment practices like Continuous Delivery (CD) and GitOps advocate for the software delivery process to be automated and repeatable. This means that the deployment process should be deterministic and should not require manual intervention. A common way of doing this is to have a pipeline that receives a commit, and then automatically deploys the build artifacts from that commit to the target environment.
As it is very rare to encounter a project with a 0% change failure rate, rolling back a deployment is something everyone needs to be prepared for.
In theory, rolling back a deployment should be as simple as deploying the previous version of the application. When it comes to versions of our application code, this works perfectly. We pull and deploy the container image corresponding to the previous version.
This strategy does not work for the database, for two reasons:
- For most migration tools,
downorrollbackis a separate command that needs to be executed specifically. This means that the deployment machinery needs to know what the current version of the target database is in order to decide whether to migrate up or down. - When we pull artifacts from a previous version, they do not contain the down files that are needed to revert the database changes back to the necessary schema - they were only created in a future commit!
These gaps mean that teams are left with two options: either they need to manually intervene to roll back the database changes, or they need to develop a custom solution that can handle the rollback in an automated way.
Down Migrations and GitOps
Going back to our main theme of exploring whether database rollbacks and GitOps can be compatible, let's expand on this last point.
The ArgoCD documentation suggests
that the way to integrate schema migrations is to use a Kubernetes Job that executes your migration tool of choice,
and to annotate the Job as a PreSync hook:
This image will typically be built as part of your CI/CD pipeline, and will contain the migration tool and the migration scripts for the relevant commit or release:
apiVersion: batch/v1
kind: Job
metadata:
name: db-migration
annotations:
argocd.argoproj.io/hook: PreSync
argocd.argoproj.io/hook-delete-policy: HookSucceeded
spec:
template:
spec:
containers:
- name: migrate
image: your-migration-image:{{ .Values.image.tag }} # Example using Helm values
restartPolicy: Never
When ArgoCD detects a new commit in the Git repository, it will create a new Job that runs the migration tool. If the
migration is successful, the Job will complete successfully, and the new version of the application will be deployed.
This will work for the up migration. But what happens when you need to roll back?
Teams commonly hit the two issues we mentioned above:
-
The deployment machinery does not know what the current version of the target database is, and therefore cannot decide whether to migrate up or down.
Unless a team has carefully thought about this and implemented a mechanism inside the image to decide what to do, the deployment machinery will always migrate up.
-
The image that is pulled for the rollback does not contain the down files that are needed to revert the database changes back to the necessary schema. Most migration tools will silently keep the database in the current state.
What are the implications?
-
The database is no longer in sync with the current Git commit, violating all GitOps principles.
-
Teams that do need to roll back the database changes are left with a manual process that requires intervention and coordination.
Operators: The GitOps Way
The Operator Pattern is a Kubernetes-native way to extend the Kubernetes API to manage additional resources. Operators typically ship two main components: a Custom Resource Definition (CRD) that defines the new resource type, and a controller that watches for changes to these resources and takes action accordingly.
The Operator Pattern is a perfect fit for managing stateful resources like databases. By extending the Kubernetes API
with a new resource type that represents a database schema, we can manage schema changes in a GitOps-friendly way.
A specialized controller can watch for changes to these resources and apply the necessary changes to the database in
a way that a naive Job cannot.
The Atlas Operator
The Atlas Operator is a Kubernetes Operator that enables you to manage your database schemas natively from your Kubernetes cluster. Built on Atlas, a database schema-as-code tool (sometimes called "like Terraform for databases"), the Atlas Operator extends the Kubernetes API to support database schema management.
Atlas has two core capabilities that are helpful to building a GitOps-friendly schema management solution:
- A sophisticated migration planner that can generates migrations by diffing the desired state of the schema with the current state of the database.
- A migration analyzer that can analyze a migration and determine whether it is safe to apply and surface risks before the migration is applied.
Declarative vs. Versioned Flows
Atlas supports two kinds of flows for managing database schema changes: declarative and versioned. They are reflected in the two main resources that the Atlas Operator manages:
Declarative: AtlasSchema
The first resource type is AtlasSchema which is used to employ the declarative flow. With AtlasSchema, you define
the desired state of the database schema in a declarative way, and the connection string to the target database.
The Operator is then responsible for generating the necessary migrations to bring the database schema to the desired
state, and applying them to the database. Here is an example of an AtlasSchema resource:
apiVersion: db.atlasgo.io/v1alpha1
kind: AtlasSchema
metadata:
name: myapp
spec:
url: mysql://root:pass@mysql:3306/example
schema:
sql: |
create table users (
id int not null auto_increment,
name varchar(255) not null,
email varchar(255) unique not null,
short_bio varchar(255) not null,
primary key (id)
);
When the AtlasSchema resource is applied to the cluster, the Atlas Operator will calculate the diff between the
database at url and the desired schema, and generate the necessary migrations to bring the database to the desired
state.
Whenever the AtlasSchema resource is updated, the Operator will recalculate the diff and apply the necessary changes
to the database.
Versioned: AtlasMigration
The second resource type is AtlasMigration which is used to employ the versioned flow. With AtlasMigration, you
define the exact migration that you want to apply to the database. The Operator is then responsible for applying any
necessary migrations to bring the database schema to the desired state.
Here is an example of an AtlasMigration resource:
apiVersion: db.atlasgo.io/v1alpha1
kind: AtlasMigration
metadata:
name: atlasmigration-sample
spec:
url: mysql://root:pass@mysql:3306/example
dir:
configMapRef:
name: "migration-dir" # Ref to a ConfigMap containing the migration files
When the AtlasMigration resource is applied to the cluster, the Atlas Operator will apply the migrations in the
directory specified in the dir field to the database at url. Similarly to classic migration tools, Atlas uses
a metadata table on the target database to track which migrations have been applied.
Rollbacks with the Atlas Operator
The Atlas Operator is designed to handle rollbacks in a GitOps-friendly way. This is where the power of the Operator Pattern really shines as it can make nuanced and intelligent decisions about how to handle changes to the managed resources.
To roll back a schema change in an ArgoCD-managed environment, you would simply revert the AtlasSchema or
AtlasMigration resource to a previous version. The Atlas Operator would then analyze the changes and generate the
necessary migrations to bring the database schema back to the desired state.
Advantages of the Operator Pattern
In the discussion above we kept talking about edge cases that arise when rolling back database schema changes, and concluded that they require manual consideration and intervention. What if we could automate this process?
The Operator Pattern is all about codifying operational knowledge into software. Let's consider how the Operator Pattern can be used to address the challenges we discussed:
-
Understanding intent. The Operator can discern between up and down migrations. By comparing between the current state of the database and the desired version, the operator decides whether to go up or down.
-
Having access to the necessary information. Contrary to a
Jobthat only has access to the image it was built with, the Operator stores metadata about the last execution as aConfigMapvia the Kubernetes API. This metadata enables the operator to migrate down even though the current image does not information about the current state. -
Intelligent Diffing. Because the Operator is built on top of Atlas's Schema-as-Code engine, it can calculate correct migrations even if the database is in an inconsistent state.
-
Safety checks. The Operator can analyze the migration and determine whether it is safe to apply. This is a critical feature that can prevent risky migrations from being applied. Depending on your policy, it can even require manual approval for specific types of changes!
Conclusion
In this talk, we explored the challenges of rolling back database schema changes in a GitOps environment. We discussed the limitations of the traditional up/down migration approach, and how the Operator Pattern can be used to build a more robust and automated solution.
If you have any questions or would like to learn more, please don't hesitate to reach out to us on our Discord server.