Pricing Changes for Atlas Pro
· 2 min read

Hey Atlas Users,
We wanted to share some important updates regarding changes to our Atlas Pro plan that will come into effect soon.
Hey Atlas Users,
We wanted to share some important updates regarding changes to our Atlas Pro plan that will come into effect soon.
Adapted from a talk given at GopherCon Israel 2024
How does Go, the project, and team behind it, test go test, the Go tool's command for running tests?
Does Go test go test using the go test command? In this article, we explore the evolution of how the Go
team tests the Go tool (go) and discuss strategies for testing command-line tools written in Go in general.
Hi Everyone,
It's been a few weeks since our last release, and I'm very excited to share with you the news of Atlas v0.27. In this release, you will find:
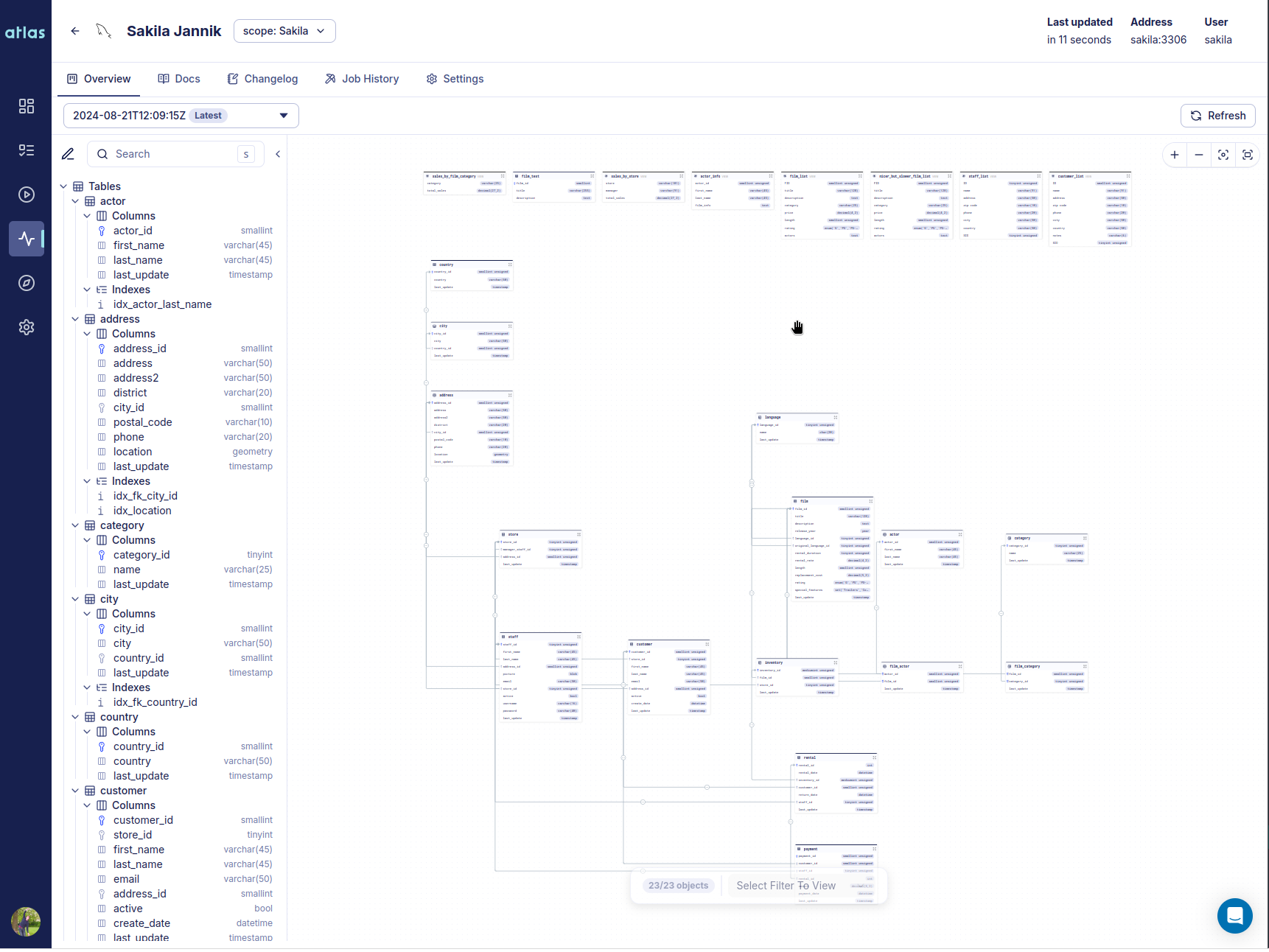
The hallmark of this release is a new product we call Atlas Schema Monitoring. Atlas Schema Monitoring provides a set of tools and features to help you manage and monitor your database schema effectively. Teams install an agent (container) on their database VPC which tracks changes to the database schema and reports metadata to the Atlas Cloud control plane. Using this metadata Atlas Schema Monitoring provides:
Starting today, we are providng one free monitored instance to all signed up Atlas users.
A Live Demo is available for you to try out.
Hi everyone,
It's been about a month since our last release, and we're excited to announce that Atlas v0.26 is now available! In this release we are happy to introduce a new feature that has been requested by many of you: support for Entity Framework Core. As part of our ever going effort to improve the quality and coverage of our documentation, we have published a set of guides on testing database schemas and migrations as well as a new GORM Portal.
Additionally, we have published an official "Supported Version Policy" and made some changes to our EULA, described below.
The pricing information in this post is outdated. Atlas no longer offers a free plan. Atlas now offers a 30-day free trial of Atlas Pro. For current pricing information, please visit the Atlas Pricing page.
Hi everyone,
We are updating you on a pricing change we will be rolling out to Atlas Cloud on March 15th, 2024.
As you know, Atlas is an open-core project, which means that while its core is an Apache 2-licensed open-source project, we are building it as a commercial, cloud-connected solution built and supported by our company, Ariga. As with any startup, our understanding of the product and the market are constantly evolving, and this pricing change is a reflection of that evolution.
Even through this change, we will keep providing the Atlas community with three options for how to consume Atlas.
Free Plan (formerly "Community Plan") - for individuals and small teams that want to unlock the full potential of Atlas. This plan will remain free forever and provides full access to all the capabilities of Atlas as a CLI as well as access to enough Atlas Cloud quota to successfully manage a single project. Support is provided via public community support channels.
Business Plan (formerly "Team Plan") - for teams professionally using Atlas beyond a single project. This plan has the same features and capabilities as the Free Plan but allows teams to purchase additional quotas if required. In addition, teams subscribing to this plan will get access to priority email support and in-app support via Intercom.
Enterprise Plan - for larger organizations looking to solve schema management at scale. This plan includes a dedicated support channel, solution engineering, and other features required for adoption by enterprises.
Hi everyone!
It's been a few weeks since our last version announcement and today I'm happy to share with you
v0.15, which includes some
very exciting improvements for Atlas:
schema apply command. In this release we have added a new "Lint and Edit" mode to this command, which
will analyze your schema changes for issues and will allow you to edit them interactively before applying them to your
database.Let's dive right in!
In this guide we will demonstrate how to use Atlas to automatically generate migrations for Microsoft SQL Server databases.
To skip the intro and go straight to the demo, click here.
As your application's data model evolves, you will need to make changes to your database schema. In today's world, where teams are expected to own their infrastructure and ship code faster than ever, it is important to have a reliable and repeatable process for managing database schema changes.
Atlas lets you manage your database schema as code. It is a modern schema management tool that applies concepts from modern DevOps tools to database schema management. Using Atlas, teams can automatically plan, verify, deploy and monitor database schema changes.
Microsoft SQL Server, one of the longest-standing database engines in our business, was first released by Microsoft in 1989. MS-SQL is the go-to database for Windows environments in many industries.
In this guide, we will demonstrate how to use Atlas to automatically generate migrations for your Microsoft SQL Server databases.
Hi everyone!
I'm very happy to share with you some of the recent improvements to Atlas, specifcially around GitHub Actions. In August of last year, we released our first version of the GitHub Actions experience for Atlas. It was a modest start, which included the ability to verify the safety and correctness of schema migrations during the CI process.
Over the past year, we have slowly added more features to the GitHub Actions experience, including the ability to sync migration directories to Atlas Cloud, deploy migrations, and even install Atlas. As often happens with quickly evolving systems, we felt that the API became complex, carrying over use cases and experiences that have become obsolete or superseded by better ones since the initial release.
At Ariga, the team developing Atlas, we have written a document named the "R&D Manifesto", which lists some the principles that we commit to as individuals and as an organization. One of them is "Obsess over APIs and DevEx" - we believe that the key to building a successful product is to provide the best possible experience to our users, and that starts with clear, consistent and composable APIs that empower our users to achieve amazing feats of engineering.
With that in mind, our team has been working hard in the past few weeks to revamp the GitHub Actions experience for Atlas. Here's a quick summary of the changes:
Hi everyone!
It's been a few weeks since our last version announcement and today I'm happy to share with you
v0.14, which includes some
very exciting improvements for Atlas:
docker push for your database migrations.Let's dive right in!
Atlas now supports AWS IAM authentication, which enables you to perform passwordless schema migrations on your
RDS databases. To use it with Atlas, add the aws_rds_token data source to your atlas.hcl configuration file:
data "aws_rds_token" "mydb" {
endpoint = "mydb.123456789012.us-east-1.rds.amazonaws.com:3306"
username = "atlas"
}
To skip the intro and jump straight to the tutorial, click here.