Atlas Project Configuration (atlas.hcl)
Config Files
Atlas config files provide a convenient way to describe and interact with multiple environments when working with Atlas. In addition, they allow you to read data from external sources, define input variables, configure linting and migration policies, and more.
By default, when running an Atlas command with the --env flag, Atlas searches for a file named atlas.hcl in the current working directory.
However, by using the -c / --config flag, you can specify the path to a config file in a different location or with a different name.
- MySQL
- MariaDB
- PostgreSQL
- SQLite
- SQL Server
- ClickHouse
- Redshift
- Snowflake
// Define an environment named "local"
env "local" {
// Declare where the schema definition resides.
// Also supported: ["file://multi.hcl", "file://schema.hcl"].
src = "file://project/schema.hcl"
// Define the URL of the database which is managed
// in this environment.
url = "mysql://user:pass@localhost:3306/schema"
// Define the URL of the Dev Database for this environment
// See: https://atlasgo.io/concepts/dev-database
dev = "docker://mysql/8/dev"
}
env "dev" {
// ... a different env
}
// Define an environment named "local"
env "local" {
// Declare where the schema definition resides.
// Also supported: ["file://multi.hcl", "file://schema.hcl"].
src = "file://project/schema.hcl"
// Define the URL of the database which is managed
// in this environment.
url = "maria://user:pass@localhost:3306/schema"
// Define the URL of the Dev Database for this environment
// See: https://atlasgo.io/concepts/dev-database
dev = "docker://maria/latest/dev"
}
env "dev" {
// ... a different env
}
// Define an environment named "local"
env "local" {
// Declare where the schema definition resides.
// Also supported: ["file://multi.hcl", "file://schema.hcl"].
src = "file://project/schema.hcl"
// Define the URL of the database which is managed
// in this environment.
url = "postgres://postgres:pass@localhost:5432/database?search_path=public&sslmode=disable"
// Define the URL of the Dev Database for this environment
// See: https://atlasgo.io/concepts/dev-database
dev = "docker://postgres/15/dev?search_path=public"
}
env "dev" {
// ... a different env
}
// Define an environment named "local"
env "local" {
// Declare where the schema definition resides.
// Also supported: ["file://multi.hcl", "file://schema.hcl"].
src = "file://project/schema.hcl"
// Define the URL of the database which is managed
// in this environment.
url = "sqlite://file.db?_fk=1"
// Define the URL of the Dev Database for this environment
// See: https://atlasgo.io/concepts/dev-database
dev = "sqlite://file?mode=memory&_fk=1"
}
env "dev" {
// ... a different env
}
// Define an environment named "local"
env "local" {
// Declare where the schema definition resides.
// Also supported: ["file://multi.hcl", "file://schema.hcl"].
src = "file://project/schema.hcl"
// Define the URL of the database which is managed
// in this environment.
url = "sqlserver://sa:pass@remote:1433?database=master"
// Define the URL of the Dev Database for this environment
// See: https://atlasgo.io/concepts/dev-database
dev = "docker://sqlserver/2022-latest"
}
env "dev" {
// ... a different env
}
// Define an environment named "local"
env "local" {
// Declare where the schema definition resides.
// Also supported: ["file://multi.hcl", "file://schema.hcl"].
src = "file://project/schema.hcl"
// Define the URL of the database which is managed
// in this environment.
url = "clickhouse://user:pass@remote:9000/default"
// Define the URL of the Dev Database for this environment
// See: https://atlasgo.io/concepts/dev-database
dev = "docker://clickhouse/23.11/default"
}
env "dev" {
// ... a different env
}
// Define an environment named "local"
env "local" {
// Declare where the schema definition resides.
// Also supported: ["file://multi.hcl", "file://schema.hcl"].
src = "file://project/schema.hcl"
// Define the URL of the database which is managed
// in this environment.
url = "redshift://user:pass@redshift-cluster:5439/example?search_path=public&sslmode=disable"
// Define the URL of the Dev Database for this environment
// See: https://atlasgo.io/concepts/dev-database
dev = "redshift://user:pass@redshift-cluster:5439/dev?search_path=public&sslmode=disable"
}
env "dev" {
// ... a different env
}
// Define an environment named "local"
env "local" {
// Declare where the schema definition resides.
// Also supported: ["file://multi.hcl", "file://schema.hcl"].
src = "file://project/schema.hcl"
// Define the URL of the database which is managed
// in this environment.
url = "snowflake://user:password@account_identifier/db"
// Define the URL of the Dev Database for this environment
// See: https://atlasgo.io/concepts/dev-database
dev = "snowflake://user:password@account_identifier/devdb"
}
env "dev" {
// ... a different env
}
Flags
Once the project configuration has been defined, you can interact with it using one of the following options:
- Env
- Custom File
- Global Config (without --env)
To run the schema apply command using the local configuration defined in atlas.hcl file located in your working directory:
atlas schema apply --env local
To run the schema apply command using the local configuration defined in atlas.hcl in arbitrary location:
atlas schema apply \
-c file://path/to/atlas.hcl \
--env local
Some commands accept global configuration blocks such as lint and
diff policies. If no env is defined, you can instruct Atlas to explicitly use the config
file using the -c (or --config) flag:
atlas migrate lint \
-c file://path/to/atlas.hcl \
--dir "file://path/to/migrations" \
--dev-url "sqlite://file?mode=memory"
Will run the schema apply command against the database that is defined for the local
environment.
env blocksIt is possible to define an env block whose name is dynamically set during command execution using the --env flag.
This is useful when multiple environments share the same configuration and the arguments are dynamically set during
execution:
env {
name = atlas.env
url = var.url
format {
migrate {
apply = format(
"{{ json . | json_merge %q }}",
jsonencode({
EnvName : atlas.env
})
)
}
}
}
Validating the Config File Atlas Pro
The atlas config validate command checks an atlas.hcl file for structural problems: unknown or
mis-nested blocks, missing or unknown attributes, mutually-exclusive options, and invalid enum values.
It reports them as file:line:column diagnostics. It is handy as a fast CI gate, or as feedback for
tools and AI agents that author atlas.hcl programmatically.
By default, the command validates file://atlas.hcl in the working directory. Use the -f / --file
flag to point it at a different file, or repeat the flag to validate several files at once:
# Validate ./atlas.hcl in the working directory.
atlas config validate
# Validate a specific file.
atlas config validate -f file://path/to/atlas.hcl
# Validate multiple files.
atlas config validate -f file://atlas.hcl -f file://atlas.dev.hcl
Because expressions are not evaluated, atlas config validate checks the config as written, not as it
resolves at runtime. A config whose shape depends on variable values (for example, a condition that
selects a different url) or on values returned by data sources may behave
differently once those are evaluated. For the fully resolved picture, run the command you are
configuring, such as schema apply or migrate diff.
Projects with Versioned Migrations
Environments may declare a migration block to configure how versioned migrations
work in the specific environment:
env "local" {
// ..
migration {
// URL where the migration directory resides.
dir = "file://migrations"
}
}
Once defined, migrate commands can use this configuration, for example:
atlas migrate validate --env local
Will run the migrate validate command against the Dev Database defined in the
local environment.
Passing Input Values
Config files may pass input values to variables defined in Atlas HCL schemas. To do this,
define an hcl_schema data source, pass it the input values, and then designate it as the
desired schema within the env block:
- atlas.hcl
- schema.hcl
data "hcl_schema" "app" {
path = "schema.hcl"
vars = {
// Variables are passed as input values to "schema.hcl".
tenant = "ariga"
}
}
env "local" {
src = data.hcl_schema.app.url
url = "sqlite://test?mode=memory&_fk=1"
}
// This variable is passed as an input value from "atlas.hcl".
variable "tenant" {
type = string
}
schema "main" {
name = var.tenant
}
Builtin Functions
file
The file function reads the content of a file and returns it as a string. The file path is relative to the project
directory or an absolute path.
variable "cloud_token" {
type = string
default = file("/var/run/secrets/atlas_token")
}
fileset
The fileset function returns the list of files that match the given pattern. The pattern is relative to the project
directory.
data "hcl_schema" "app" {
paths = fileset("schema/*.pg.hcl")
}
getenv
The getenv function returns the value of the environment variable named by the key. It returns an empty string if the
variable is not set.
env "local" {
url = getenv("DATABASE_URL")
}
Project Input Variables
atlas.hcl file may also declare input variables that can be supplied to the CLI at runtime. For example:
variable "tenant" {
type = string
}
data "hcl_schema" "app" {
path = "schema.hcl"
vars = {
// Variables are passed as input values to "schema.hcl".
tenant = var.tenant
}
}
env "local" {
src = data.hcl_schema.app.url
url = "sqlite://test?mode=memory&_fk=1"
}
To set the value for this variable at runtime, use the --var flag:
atlas schema apply --env local --var tenant=rotemtam
It is worth mentioning that when running Atlas commands within a project using
the --env flag, all input values supplied at the command-line are passed only
to the config file, and not propagated automatically to children schema files.
This is done with the purpose of creating an explicit contract between the environment
and the schema file.
Supported Blocks
Atlas configuration files support various blocks and attributes. Below are the common examples; see the Atlas Config Schema for the full list.
Input Variables
Config files support defining input variables that can be injected through the CLI, read more here.
type- The type constraint of a variable.default- Define if the variable is optional by setting its default value.
variable "tenants" {
type = list(string)
}
variable "url" {
type = string
default = "mysql://root:pass@localhost:3306/"
}
variable "cloud_token" {
type = string
default = getenv("ATLAS_TOKEN")
}
env "local" {
// Reference an input variable.
url = var.url
}
Local Values
The locals block allows defining a list of local variables that can be reused multiple times in the project.
locals {
tenants = ["tenant_1", "tenant_2"]
base_url = "mysql://${var.user}:${var.pass}@${var.addr}"
// Reference local values.
db1_url = "${local.base_url}/db1"
db2_url = "${local.base_url}/db2"
}
Atlas Block
The atlas block allows configuring your Atlas account. The supported attributes are:
org- Specifies the organization to log in to. If Atlas executes usingatlas.hclwithout logging in to the specified organization, the command will be aborted.token- CI/CD pipelines can use thetokenattribute for Atlas authentication.
atlas {
cloud {
org = "acme"
}
}
Atlas Pro users are advised to set the org in atlas.hcl to ensure that any engineer interacting with Atlas in the
project context is running in logged-in mode. This ensures Pro features are enabled and the correct migration is generated.
Data Sources
Data sources enable users to retrieve information stored in an external service or database. The currently supported data sources are:
sqlexternalruntimevarhcl_schemaexternal_schemacomposite_schemablob_dircloud_databasesremote_dirtemplate_diraws_rds_tokenaws_dsql_tokengcp_cloudsql_tokenhttp
Data sources are evaluated only if they are referenced by top-level blocks like locals or variables, or by the
selected environment, for instance, atlas schema apply --env dev.
Data source: sql
The sql data source allows executing SQL queries on a database and using the results in the project.
Arguments
url- The URL of the target database.query- Query to execute.args- Optional arguments for any placeholder parameters in the query.
Attributes
count- The number of returned rows.values- The returned values. e.g.list(string).value- The first value in the list, ornil.
- MySQL
- PostgreSQL
data "sql" "tenants" {
url = var.url
query = <<EOS
SELECT `schema_name`
FROM `information_schema`.`schemata`
WHERE `schema_name` LIKE ?
EOS
args = [var.pattern]
}
env "prod" {
// Reference a data source.
for_each = toset(data.sql.tenants.values)
url = urlsetpath(var.url, each.value)
}
data "sql" "tenants" {
url = var.url
query = <<EOS
SELECT schema_name
FROM information_schema.schemata
WHERE schema_name LIKE $1
EOS
args = [var.pattern]
}
env "prod" {
// Reference a data source.
for_each = toset(data.sql.tenants.values)
url = urlqueryset(var.url, "search_path", each.value)
}
Multi-Column Queries
For more advanced use cases, such as fetching tenant metadata for deployment rollout strategies,
the sql data source can return multiple columns per row. When a query returns multiple columns, each element in values
is a map containing all columns:
- MySQL
- PostgreSQL
data "sql" "tenants" {
url = var.url
query = <<EOS
SELECT
`org`.`name`,
`org`.`schema`,
`plan`.`tier`
FROM `admin`.`organizations` AS `org`
LEFT JOIN `admin`.`plans` AS `plan`
ON `org`.`plan_id` = `plan`.`id`
EOS
}
deployment "staged" {
variable "name" {
type = string
}
variable "tier" {
type = string
}
// Stage 1: Deploy to internal tenants first (one at a time).
// Acts as a canary to catch issues before external rollout.
group "internal" {
match = startswith(var.name, "my-company")
}
// Stage 2: Roll out to free-tier tenants in parallel.
group "free" {
match = var.tier == "FREE"
parallel = 10
on_error = CONTINUE
depends_on = [group.internal]
}
// Stage 3: Finally, deploy to paying customers.
// Lower parallelism for more controlled rollout.
group "paid" {
parallel = 3
depends_on = [group.free]
}
}
env "prod" {
for_each = toset(data.sql.tenants.values)
url = urlsetpath(var.url, each.value.schema)
rollout {
deployment = deployment.staged
vars = {
name = each.value.name
tier = each.value.tier
}
}
}
data "sql" "tenants" {
url = var.url
query = <<EOS
SELECT
org.name,
org.schema,
COALESCE(plan.tier, 'FREE') AS tier
FROM admin.organizations AS org
LEFT JOIN admin.plans AS plan
ON org.plan_id = plan.id
EOS
}
deployment "staged" {
variable "name" {
type = string
}
variable "tier" {
type = string
}
// Stage 1: Deploy to internal tenants first (one at a time).
// Acts as a canary to catch issues before external rollout.
group "internal" {
match = startswith(var.name, "my-company")
}
// Stage 2: Roll out to free-tier tenants in parallel.
group "free" {
match = var.tier == "FREE"
parallel = 10
on_error = CONTINUE
depends_on = [group.internal]
}
// Stage 3: Finally, deploy to paying customers.
// Lower parallelism for more controlled rollout.
group "paid" {
parallel = 3
depends_on = [group.free]
}
}
env "prod" {
for_each = toset(data.sql.tenants.values)
url = urlqueryset(var.url, "search_path", each.value.schema)
rollout {
deployment = deployment.staged
vars = {
name = each.value.name
tier = each.value.tier
}
}
}
Data source: external
The external data source allows the execution of an external program and uses its output in the project.
Arguments
program- The first element of the string is the program to run. The remaining elements are optional command line arguments.working_dir- The working directory to run the program from. Defaults to the current working directory.
Attributes
- The command output is a
stringtype with no attributes.
Usage example
data "external" "dot_env" {
program = [
"npm",
"run",
"load-env.js"
]
}
locals {
dot_env = jsondecode(data.external.dot_env)
}
env "local" {
src = local.dot_env.URL
dev = "docker://mysql/8/dev"
}
Data source: runtimevar
Arguments
url- The URL identifies the variable. See, the CDK documentation for more information. Usetimeout=Xto control the operation's timeout. If not specified, the timeout defaults to 10s.
Attributes
- The loaded variable is a
stringtype with no attributes.
- GCP Runtime Configurator
- GCP Secret Manager
- AWS Parameter Store
- AWS Secrets Manager
- HTTP
- File
- HashiVault
The data source uses Application Default Credentials by default;
if you have authenticated via gcloud auth application-default login,
it will use those credentials.
data "runtimevar" "db" {
url = "gcpruntimeconfig://projects/<project>/configs/<config-id>/variables/<variable>?decoder=string"
}
env "dev" {
src = "file://schema.my.hcl"
url = "mysql://root:pass@host:3306/${data.runtimevar.db}"
}
Usage example
gcloud auth application-default login
atlas schema apply --env dev
GOOGLE_APPLICATION_CREDENTIALS="/path/to/credentials.json" atlas schema apply --env dev
The data source uses Application Default Credentials by default;
if you have authenticated via gcloud auth application-default login,
it will use those credentials.
data "runtimevar" "pass" {
url = "gcpsecretmanager://projects/<project>/secrets/<secret>"
}
env "dev" {
src = "file://schema.my.hcl"
url = "mysql://root:${data.runtimevar.pass}@host:3306/database"
}
Usage example
gcloud auth application-default login
atlas schema apply --env dev
GOOGLE_APPLICATION_CREDENTIALS="/path/to/credentials.json" atlas schema apply --env dev
The data source provides two ways to work with AWS Parameter Store:
- If the
awssdkquery parameter is not set or is set tov1, a default AWS Session will be created with the SharedConfigEnable option enabled; if you have authenticated with the AWS CLI, it will use those credentials. - If the
awssdkquery parameter is set tov2, the data source will create an AWS Config based on the AWS SDK V2.
Using local AWS Profiles or assuming an IAM role:
- Using a local AWS Credentials profile is supported in the
v2mode. Theprofilequery parameter is used to specify the profile name. To use profiles setawssdk=v2andprofile=<profile>in the URL. - Assuming an IAM role is supported in the
v2mode. Therolequery parameter is used to specify the role ARN. To assume a role setawssdk=v2androle=arn:aws:iam::<account-id>:role/<role-name>in the URL.
data "runtimevar" "db" {
url = "awsparamstore://<name>?region=<region>&decoder=string"
}
data "runtimevar" "from_profile" {
url = "awsparamstore://<name>?region=<region>&decoder=string&awssdk=v2&profile=<profile>"
}
data "runtimevar" "from_role" {
url = "awsparamstore://<name>?region=<region>&decoder=string&awssdk=v2&role=arn:aws:iam::<account-id>:role/<role-name>"
}
env "dev" {
src = "file://schema.my.hcl"
url = "mysql://root:pass@host:3306/${data.runtimevar.db}"
}
It's a common case when you use the hierarchies format for your parameters in AWS Parameter Store. So the url should
contain the path to the hierarchy, for example awsparamstore:///production/tenant_a/password?region=<region>&decoder=string (there are three slashes after the protocol).
Usage example
# Default credentials reside in ~/.aws/credentials.
atlas schema apply --env dev
AWS_ACCESS_KEY_ID="ACCESS_ID" AWS_SECRET_ACCESS_KEY="SECRET_KEY" atlas schema apply --env dev
The data source provides two ways to work with AWS Secrets Manager:
- If the
awssdkquery parameter is not set or is set tov1, a default AWS Session will be created with the SharedConfigEnable option enabled; if you have authenticated with the AWS CLI, it will use those credentials. - If the
awssdkquery parameter is set tov2, the data source will create an AWS Config based on the AWS SDK V2.
Using local AWS Profiles or assuming an IAM role:
- Using a local AWS Credentials profile is supported in the
v2mode. Theprofilequery parameter is used to specify the profile name. To use profiles setawssdk=v2andprofile=<profile>in the URL. - Assuming an IAM role is supported in the
v2mode. Therolequery parameter is used to specify the role ARN. To assume a role setawssdk=v2androle=arn:aws:iam::<account-id>:role/<role-name>in the URL.
data "runtimevar" "pass" {
url = "awssecretsmanager://<secret>?region=<region>"
}
data "runtimevar" "pass_from_profile" {
url = "awssecretsmanager://<secret>?region=<region>&awssdk=v2&profile=<profile>"
}
data "runtimevar" "pass_from_role" {
url = "awssecretsmanager://<secret>?region=<region>&awssdk=v2&role=arn:aws:iam::<account-id>:role/<role-name>"
}
env "dev" {
src = "file://schema.my.hcl"
url = "mysql://root:${data.runtimevar.pass}@host:3306/database"
}
Usage example
# Default credentials reside in ~/.aws/credentials.
atlas schema apply --env dev
AWS_ACCESS_KEY_ID="ACCESS_ID" AWS_SECRET_ACCESS_KEY="SECRET_KEY" atlas schema apply --env dev
data "runtimevar" "pass" {
url = "http://service.com/foo.txt"
}
env "dev" {
src = "file://schema.my.hcl"
url = "mysql://root:${data.runtimevar.pass}@host:3306/database"
}
data "runtimevar" "pass" {
url = "file:///path/to/config.txt"
}
env "dev" {
src = "file://schema.my.hcl"
url = "mysql://root:${data.runtimevar.pass}@host:3306/database"
}
The HashiVault data source is available only to Atlas Pro users. To use this feature, run:
atlas login
The data source uses HashiCorp Vault to securely retrieve secrets from the KV Secrets Engine (supports both v1 and v2). The data source uses the Vault address and token from the VAULT_ADDR and VAULT_TOKEN environment variables for authentication.
The output from Vault returns only the secret values as a raw JSON object (metadata is not included). Use jsondecode() to parse the response and access individual values.
data "runtimevar" "vault" {
url = "hashivault://secret/data/database"
}
locals {
vault = jsondecode(data.runtimevar.vault)
}
env "dev" {
url = "postgres://user:${local.vault.password}@host:5432/database?sslmode=disable"
src = "file://schema.pg.hcl"
}
Usage example
VAULT_ADDR="https://vault.example.com:8200" VAULT_TOKEN="your-vault-token" atlas schema apply --env dev
Data source: hcl_schema
The hcl_schema data source allows the loading of an Atlas HCL schema from a file or directory, with optional variables.
Arguments
path- The path to the HCL file or directory (cannot be used withpaths).paths- List of paths to HCL files or directories (cannot be used withpath).vars- A map of variables to pass to the HCL schema.
Attributes
url- The URL of the loaded schema.
- atlas.hcl
- schema.hcl
variable "tenant" {
type = string
}
data "hcl_schema" "app" {
path = "schema.hcl"
vars = {
tenant = var.tenant
}
}
env "local" {
src = data.hcl_schema.app.url
url = "sqlite://test?mode=memory&_fk=1"
}
// This variable is passed as an input value from "atlas.hcl".
variable "tenant" {
type = string
}
schema "main" {
name = var.tenant
}
Data source: external_schema
The external_schema data source enables the import of an SQL schema from an external program into Atlas' desired state.
With this data source, users have the flexibility to represent the desired state of the database schema in any language.
Arguments
program- The first element of the string is the program to run. The remaining elements are optional command line arguments.working_dir- The working directory to run the program from. Defaults to the current working directory.
Attributes
url- The URL of the loaded schema.
Usage example
By running atlas migrate diff with the given configuration, the external program will be executed and its loaded state
will be compared against the current state of the migration directory. In case of a difference between the two states,
a new migration file will be created with the necessary SQL statements.
data "external_schema" "graph" {
program = [
"npm",
"run",
"generate-schema"
]
}
env "local" {
src = data.external_schema.graph.url
dev = "docker://mysql/8/dev"
migration {
dir = "file://migrations"
}
}
Data source: composite_schema Atlas Pro
The composite_schema data source allows the composition of multiple Atlas schemas into a unified schema graph. This
functionality is useful when projects schemas are split across various sources such as HCL, SQL, or application ORMs.
For example, each service have its own database schema, or an ORM schema is extended or relies on other database schemas.
Referring to the url returned by this data source allows reading the entire project schemas as a single unit by any of
the Atlas commands, such as migrate diff, schema apply, or schema inspect.
Arguments
schema - one or more blocks containing the URL to read the schema from.
Usage Details
Mapping to Database Schemas
The name of the schema block represents the database schema to be created in the composed graph. For example, the
following schemas refer to the public and private schemas within a PostgreSQL database:
data "composite_schema" "project" {
schema "public" {
url = ...
}
schema "private" {
url = ...
}
}
Schema Dependencies
The order of the schema blocks defines the order in which Atlas will load the schemas to compose the entire database
graph. This is useful in the case of dependencies between the schemas. For example, the following schemas refer to the
inventory and auth schemas, where the auth schema depends on the inventory schema and therefore should be loaded
after it:
data "composite_schema" "project" {
schema "inventory" {
url = ...
}
schema "auth" {
url = ...
}
}
Schema Composition
Defining multiple schema blocks with the same name enables extending the same database schema from multiple sources.
For example, the following configuration shows how an ORM schema, which relies on database types that cannot be defined
within the ORM itself, can load them separately from another schema source that supports it:
data "composite_schema" "project" {
schema "public" {
url = "file://types.pg.hcl"
}
schema "public" {
url = "ent://ent/schema"
}
}
Labeled vs. Unlabeled Schema Blocks
Note, if the schema block is labeled (e.g., schema "public"), the schema will be created if it does not exist,
and the computation for loading the state from the URL will be done within the scope of this schema.
If the schema block is unlabeled (e.g., schema { ... }), no schema will be created, and the computation for loading
the state from the URL will be done within the scope of the database. Read more about this in Schema vs. Database Scope
doc.
Attributes
url- The URL of the composite schema.
Usage example
By running atlas migrate diff with the given configuration, Atlas loads the inventory schema from the SQLAlchemy schema,
the graph schema from ent/schema, and the auth and internal schemas from HCL and SQL schemas defined in
Atlas format. Then, the composite schema, which represents these four schemas combined, will be compared against the
current state of the migration directory. In case of a difference between the two states, a new migration file will be
created with the necessary SQL statements.
data "composite_schema" "project" {
schema "inventory" {
url = data.external_schema.sqlalchemy.url
}
schema "graph" {
url = "ent://ent/schema"
}
schema "auth" {
url = "file://path/to/schema.hcl"
}
schema "internal" {
url = "file://path/to/schema.sql"
}
}
env "dev" {
src = data.composite_schema.project.url
dev = "docker://postgres/15/dev"
migration {
dir = "file://migrations"
}
}
Data source: remote_dir
The remote_dir data source reads the state of a migration directory from Atlas Cloud. For
instructions on how to connect a migration directory to Atlas Cloud, please refer to the cloud documentation.
Arguments
name- The slug of the migration directory, as defined in Atlas Cloud.tag(optional) - The tag of the migration directory, such as Git commit. If not specified, the latest tag (e.g.,masterbranch) will be used.
Attributes
url- A URL to the loaded migration directory.
The remote_dir data source predates the atlas:// URL scheme. The example below is equivalent to executing Atlas with
--dir "atlas://myapp".
variable "database_url" {
type = string
default = getenv("DATABASE_URL")
}
data "remote_dir" "migrations" {
// The slug of the migration directory in Atlas Cloud.
// In this example, the directory is named "myapp".
name = "myapp"
}
env {
// Set environment name dynamically based on --env value.
name = atlas.env
url = var.database_url
migration {
dir = data.remote_dir.migrations.url
}
}
Usage example
ATLAS_TOKEN="<ATLAS_TOKEN>" \
atlas migrate apply \
--url "<DATABASE_URL>" \
-c file://path/to/atlas.hcl \
--env prod
DATABASE_URL="<DATABASE_URL>" ATLAS_TOKEN="<ATLAS_TOKEN>" \
atlas migrate apply \
-c file://path/to/atlas.hcl \
--env prod
In case the cloud block was activated with a valid token, Atlas logs migration runs in your cloud account
to facilitate the monitoring and troubleshooting of executed migrations. The following is a demonstration of how it
appears in action:
Screenshot example
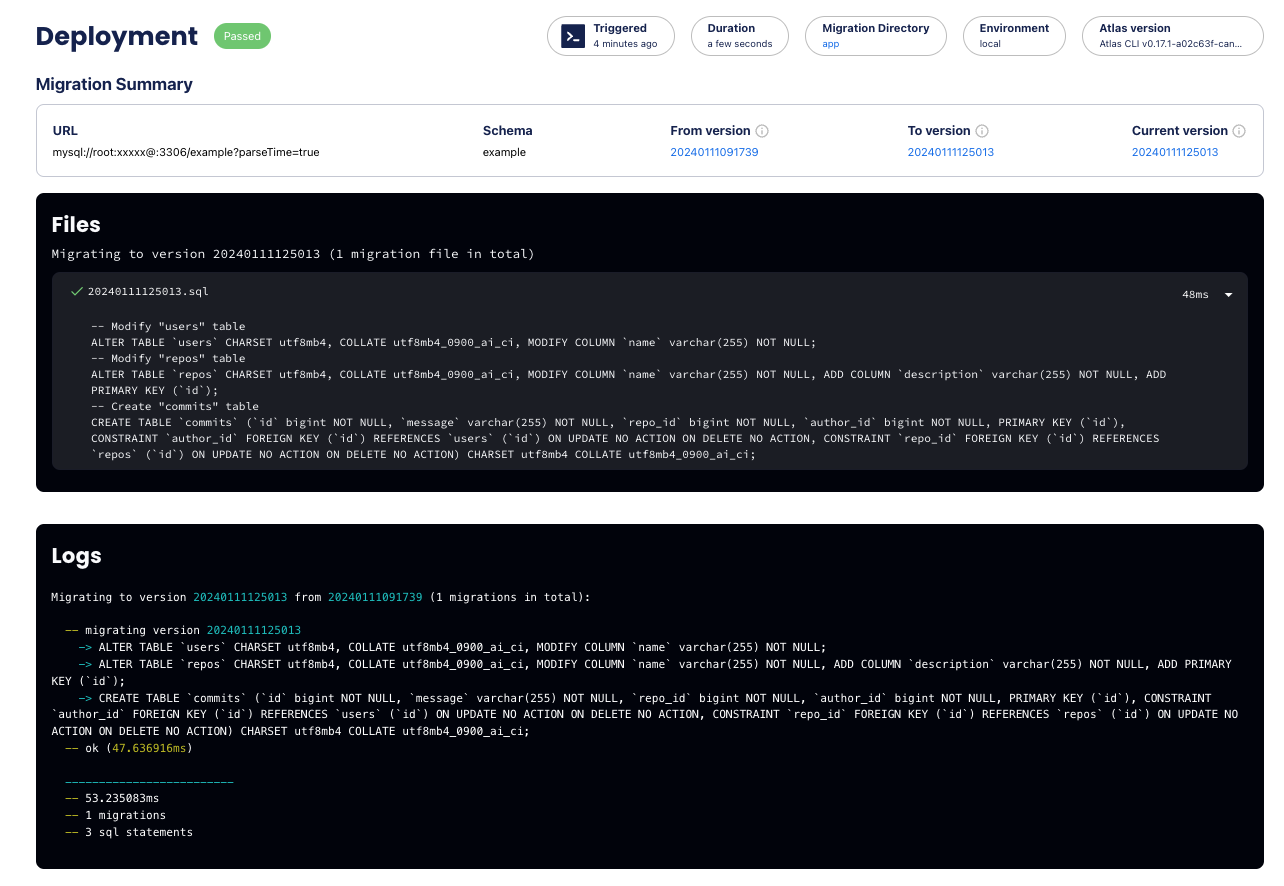
Data source: template_dir
The template_dir data source renders a migration directory from a template directory. It does this by parsing the
entire directory as Go templates, executing top-level (template) files that
have the .sql file extension, and generating an in-memory migration directory from them.
Arguments
path- A path to the template directory.vars- A map of variables to pass to the template.
Attributes
url- A URL to the generated migration directory.
- Read only templates
- Variables shared between HCL and directory
variable "path" {
type = string
description = "A path to the template directory"
}
data "template_dir" "migrations" {
path = var.path
vars = {
Key1 = "value1"
Key2 = "value2"
// Pass the --env value as a template variable.
Env = atlas.env
}
}
env "dev" {
url = var.url
migration {
dir = data.template_dir.migrations.url
}
}
variable "schema_name" {
type = string
default = "Database schema name injected to both migrations directory and HCL schema"
}
data "hcl_schema" "app" {
path = "path/to/schema.hcl"
vars = {
schema_name = var.schema_name
}
}
data "template_dir" "migrations" {
path = "path/to/directory"
vars = {
schema_name = var.schema_name
}
}
env "local" {
src = data.hcl_schema.app.url
dev = "sqlite://file?mode=memory&_fk=1"
migration {
dir = data.template_dir.migrations.url
}
}
Data source: blob_dir Atlas Pro
The blob_dir use the gocloud.dev/blob to open the bucket and read the migration directory from it.
It is useful for reading migration directories from cloud storage providers such as AWS S3.
Atlas only requires the read permission to the bucket.
Arguments
url- The URL of the blob storage bucket. The URL should be in the formats3://bucket-name/path/to/directoryfor AWS.
Attributes��
url- A URL to the generated migration directory.
data "blob_dir" "migrations" {
url = "s3://my-bucket/path/to/migrations?profile=aws-profile"
}
env "dev" {
url = var.url
migration {
dir = data.blob_dir.migrations.url
}
}
You can provide the profile query parameter to use a specific AWS profile from your local AWS credentials file. Or set the
credentials using environment variables: AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY.
Data source: cloud_databases Atlas Pro
The cloud_databases lists databases from Atlas Cloud. It can be used to dynamically
retrieve migration status for different environments.
Arguments
repo- The slug of the Migration directory, as defined in Atlas Cloud.env- The environment name to filter the databases by.
Attributes
targets- List of databases matching the criteria.name- The name of the database.env- The environment name of the database.url- The database URL with sensitive information redacted.status- The migration status of the database. (PENDING,SYNCED, orFAILED)PENDING- The database that is not in the latest version of the the migration directory.SYNCED- The database that is in the latest version of the the migration directory.FAILED- The database that had error in the last deployment to it.
current_version- The current migration version applied to the database.
This data source is helpful to implement the promotion workflow between environments. For example, as SOC 2 requires
that migration files must be deployed to lower environments before being applied to production, the following
configuration promotes the migration version from the dev environment to the prod environment.
data "cloud_databases" "dev" {
repo = "my-app"
env = "dev"
}
env "prod" {
url = var.url
migration {
dir = "atlas://my-app"
# Promote the migration version from the `dev` environment.
to_version = data.cloud_databases.dev.targets[0].current_version
}
}
See the environment promotion guide for a full implementation walkthrough. The same
database statuses are also available from the CLI via atlas cloud database list.
Data source: aws_rds_token
The aws_rds_token data source generates a short-lived token for an AWS RDS database
using IAM Authentication.
To use this data source:
- Enable IAM Authentication for your database. For instructions on how to do this, see the AWS documentation.
- Create a database user and grant it permission to authenticate using IAM, see the AWS documentation for instructions.
- Create an IAM role with the
rds-db:connectpermission for the specific database and user. For instructions on how to do this, see the AWS documentation.
Arguments
region- The AWS region of the database (Optional).endpoint- The endpoint of the database (hostname:port).username- The database user to authenticate as.profile- The AWS profile to use for authentication (Optional).
Attributes
- The loaded variable is a
stringtype with no attributes. Notice that the token contains special characters that need to be escaped when used in a URL. To escape the token, use theurlescapefunction.
Example
locals {
user = "iamuser"
endpoint = "hostname-of-db.example9y7k.us-east-1.rds.amazonaws.com:5432"
}
data "aws_rds_token" "db" {
region = "us-east-1"
endpoint = local.endpoint
username = local.user
}
env "rds" {
url = "postgres://${local.user}:${urlescape(data.aws_rds_token.db)}@${local.endpoint}/postgres"
}
Data source: aws_dsql_token
The aws_dsql_token data source generates a short-lived token for Amazon Aurora DSQL
using IAM authentication.
To use this data source:
- Make AWS credentials available to Atlas using environment variables, a shared profile, or an assumed role.
- Grant
dsql:DbConnectAdminwhen connecting asadmin, ordsql:DbConnectwhen connecting as a custom database role. - If you connect as a custom database role, map your IAM identity to that role with
AWS IAM GRANT.
Arguments
endpoint- The Aurora DSQL cluster endpoint, for examplecluster-id.dsql.us-east-1.on.aws.region- The AWS region of the cluster (Optional). If not set, Atlas uses the configured AWS region.profile- The AWS profile to use for authentication (Optional).role_arn- ARN of the role to assume for generating the token (Optional).admin- Iftrue, generates an admin auth token. Iffalseor omitted, Atlas generates a regular user auth token.
Attributes
- The loaded variable is a
stringtype with no attributes. Notice that the token contains special characters that need to be escaped when used in a URL. To escape the token, use theurlescapefunction.
Example
locals {
endpoint = "cluster-id.dsql.us-east-1.on.aws"
}
data "aws_dsql_token" "db" {
endpoint = local.endpoint
region = "us-east-1"
admin = true
}
env "dsql" {
url = "dsql://admin:${urlescape(data.aws_dsql_token.db)}@${local.endpoint}:5432/postgres?sslmode=require"
}
See the Aurora DSQL auth token guide for a full workflow.
Data source: gcp_cloudsql_token
The gcp_cloudsql_token data source generates a short-lived token for an GCP CloudSQL database
using IAM Authentication.
To use this data source:
- Enable IAM Authentication for your database. For instructions on how to do this, see the GCP documentation.
- Create a database user and grant it permission to authenticate using IAM, see the GCP documentation for instructions.
Attributes
- The loaded variable is a
stringtype with no attributes. Notice that the token contains special characters that need to be escaped when used in a URL. To escape the token, use theurlescapefunction.
Example
locals {
user = "iamuser"
endpoint = "34.143.100.1:3306"
}
data "gcp_cloudsql_token" "db" {}
env "rds" {
url = "mysql://${local.user}:${urlescape(data.gcp_cloudsql_token.db)}@${local.endpoint}/?allowCleartextPasswords=1&tls=skip-verify&parseTime=true"
}
The allowCleartextPasswords and tls parameters are required for the MySQL driver to connect to CloudSQL. For PostgreSQL, use sslmode=require to connect to the database.
Data source: http Atlas Pro
The http data source makes an HTTP GET/HEAD/POST request to the given URL and exports information about the response. The given URL may be either an http or https URL.
Arguments
-
url- The URL for the request. Supported schemes arehttpandhttps. -
method- The HTTP Method for the request. Allowed methods are a subset of methods defined in RFC7231 namely,GET,HEAD, andPOST.POSTsupport is only intended for read-only URLs, such as submitting a search. If omitted, the default method isGET. -
request_headers- A map of request header field names and values. -
request_body- The request body as a string. -
request_timeout_ms- The request timeout in milliseconds. -
ca_cert_pem- Certificate Authority (CA) in PEM (RFC 1421) format. -
client_cert_pem- Client certificate in PEM (RFC 1421) format. -
client_key_pem- Client key in PEM (RFC 1421) format. -
insecure- Disables verification of the server's certificate chain and hostname. Defaults tofalse. -
retry- Retry request configuration. By default there are no retries. Configuring this block will result in retries if an error is returned by the client (e.g., connection errors) or if a 5xx-range (except 501) status code is received.-
attempts- The number of times the request is to be retried. For example, if 2 is specified, the request will be tried a maximum of 3 times. -
min_delay_ms- The minimum delay between retry requests in milliseconds. -
max_delay_ms- The maximum delay between retry requests in milliseconds.
-
Attributes
-
url- The URL used for the request. -
response_headers- A map of response header field names and values. Duplicate headers are concatenated according to RFC2616. -
response_body- The response body returned as a string. -
response_body_base64- The response body encoded as base64 (standard) as defined in RFC 4648. -
status_code- The HTTP response status code.
Example
data "http" "example" {
url = "https://service.example.com/search?q=atlas"
method = "GET"
request_headers = {
"Accept" = "application/json"
}
request_timeout_ms = 5000
retry {
attempts = 2
min_delay_ms = 100
max_delay_ms = 1000
}
}
env "dev" {
src = "file://schema.my.hcl"
url = "mysql://root:${urlescape(jsondecode(data.http.example.response_body).password)}@host:3306/database"
}
-
client_cert_pemandclient_key_pemmust be set together. -
ca_cert_pemandinsecureare mutually exclusive. -
When configuring retries,
max_delay_msmust be at leastmin_delay_ms.
Exporters Atlas Pro
Exporters provide a declarative way to write Atlas command outputs to files or send them to external
services. They are configured in atlas.hcl and referenced in the relevant command's configuration block.
The currently supported exporters are:
Exporter: sql
The sql exporter exports the inspected schema as SQL structured directory.
Arguments
path(required) - Output path. Can be a file path for single-file output, or a directory path when usingsplit_by.indent(optional) - Indentation string. Defaults to" "(two spaces). Use"\t"for tabs.split_by(optional) - Split strategy. Currently onlyobjectis supported, which creates a file per database object.naming(optional) - File naming convention when splitting:lower(default),same,upper, ortitle.
Examples
- Single File
- Split by Object
exporter "sql" "schema_file" {
path = "schema.sql"
indent = " "
}
env "prod" {
url = getenv("DB_URL")
export {
schema {
inspect = exporter.sql.schema_file
}
}
}
atlas schema inspect --env prod --export
exporter "sql" "schema_dir" {
path = "schema/sql"
split_by = object
naming = lower
}
env "prod" {
url = getenv("DB_URL")
export {
schema {
inspect = exporter.sql.schema_dir
}
}
}
When using split_by = object, the output directory structure looks like:
schema/sql/
├── schemas
│ └── public
│ ├── public.sql
│ └── tables
│ ├── users.sql
│ └── posts.sql
└── main.sql
Exporter: hcl
The hcl exporter exports the inspected schema as HCL files.
Arguments
path(required) - Output path. Can be a file path for single-file output, or a directory path when usingsplit_by.split_by(optional) - Split strategy:object,schema, ortype.object- Each schema gets its own directory, a subdirectory for each object type, and a file for each object.schema- Each schema gets its own file.type- Each object type gets its own file.
naming(optional) - File naming convention when splitting:lower(default),same,upper, ortitle.ext(optional) - File extension for split files. Defaults to.hcl. It is recommended to use database-specific extensions like.pg.hclfor PostgreSQL or.my.hclfor MySQL.
Examples
- Single File
- Split by Object
exporter "hcl" "schema_file" {
path = "schema.pg.hcl"
}
env "prod" {
url = getenv("DB_URL")
export {
schema {
inspect = exporter.hcl.schema_file
}
}
}
exporter "hcl" "schema_dir" {
path = "schema/hcl"
split_by = object
naming = lower
ext = ".pg.hcl"
}
env "prod" {
url = getenv("DB_URL")
export {
schema {
inspect = exporter.hcl.schema_dir
}
}
}
When using split_by = object, the output directory structure looks like:
schema/hcl/
└── schemas
└── public
└── tables
├── users.pg.hcl
└── posts.pg.hcl
Exporter: http
The http exporter sends schema inspection results to an HTTP endpoint. This is useful for webhook integrations,
schema registries, or any external service that needs to receive schema updates.
Arguments
url(required) - The URL for the request. Supported schemes arehttpandhttps.method(required) - HTTP method:GET,POST,PUT,PATCH, etc.body(optional) - Static request body as a string. Mutually exclusive withbody_template.body_template(optional) - Go template for dynamic request body. Mutually exclusive withbody.headers(optional) - Map of HTTP headers.request_timeout_ms(optional) - Request timeout in milliseconds.ca_cert_pem(optional) - CA certificate in PEM format for TLS verification.client_cert_pem(optional) - Client certificate in PEM format for mTLS.client_key_pem(optional) - Client key in PEM format for mTLS.insecure(optional) - Skip TLS verification. Defaults tofalse.retry(optional block) - Retry configuration.attempts- Number of retry attempts.min_delay_ms- Minimum delay between retries in milliseconds.max_delay_ms- Maximum delay between retries in milliseconds.
Template Functions
The body_template field supports Go templates with the following functions. For example:
{{ sql . }}- SQL representation of the schema.{{ .MarshalHCL }}- HCL representation of the schema.{{ json . }}- JSON representation of the schema.{{ mermaid . }}- Mermaid diagram representation.
Examples
variable "webhook_token" {
type = string
default = getenv("WEBHOOK_TOKEN")
}
exporter "http" "webhook" {
url = "https://api.example.com/schemas"
method = "POST"
body_template = "{{ sql . }}"
headers = {
"Content-Type" = "text/plain"
"Authorization" = "Bearer ${var.webhook_token}"
}
request_timeout_ms = 30000
retry {
attempts = 3
min_delay_ms = 1000
max_delay_ms = 5000
}
}
env "prod" {
url = getenv("DB_URL")
export {
schema {
inspect = exporter.http.webhook
}
}
}
Exporter: multi
The multi exporter chains multiple exporters together, allowing you to export the schema to multiple destinations
in a single operation.
Arguments
exporters(required) - List of exporter references to execute.on_error(optional) - Error handling mode:FAIL(default) - Stop on first error.CONTINUE- Continue executing remaining exporters but return combined error at the end.IGNORE- Silently ignore errors and continue.
Examples
exporter "sql" "sql_file" {
path = "schema.sql"
}
exporter "hcl" "hcl_file" {
path = "schema.pg.hcl"
}
exporter "http" "webhook" {
url = "https://api.example.com/schemas"
method = "POST"
body_template = "{{ sql . }}"
}
exporter "multi" "all" {
exporters = [
exporter.sql.sql_file,
exporter.hcl.hcl_file,
exporter.http.webhook,
]
on_error = CONTINUE
}
env "prod" {
url = getenv("DB_URL")
export {
schema {
inspect = exporter.multi.all
}
}
}
Environments
The env block defines an environment block that can be selected by using the --env flag.
Arguments
-
for_each- A meta-argument that accepts a map or a set of strings and is used to compute anenvinstance for each set or map item. See the example below. -
src- The URL of or reference to for the desired schema of this environment. For example:file://schema.hclfile://schema.sqlfile://relative/path/to/file.hcl- Directories are also accepted:
file://schema/ - Lists are accepted as well:
env "local" {
src = [
"file://a.hcl",
"file://b.hcl"
]
} - As mentioned, references to data sources such as
external_schemaorcomposite_schemaare a valid value for thesrcattribute.
-
url- The URL of the target database. -
dev- The URL of the Dev Database. -
schemas- A list of strings defines the schemas that Atlas manages. -
exclude- A list of strings defines glob patterns used to filter resources on inspection. -
migration- A block defines the migration configuration of the env.dir- The URL to the migration directory.baseline- An optional version to start the migration history from. Read more here.exec_order- Set the file execution order [LINEAR(default),LINEAR_SKIP,NON_LINEAR]. Read more here.lock_timeout- An optional timeout to wait for a database lock to be released. Defaults to10s.revisions_schema- An optional name to control the schema that the revisions table resides in.skip_report- If set totrue, skip reporting migrations to Atlas Cloud. Useful for preview environments (e.g., PR previews) where reporting creates noise.repo. - The repository configuration for the migrations directory in the registry.name- The repository name.backup- Optional backup repository URLs for migration directories. See Backup Repository Configuration.
-
schema- The configuration for the desired schema.src- The URL to the desired schema state.repo- The repository configuration for the desired schema in the registry.name- The repository name.
mode- A block that configures the schema inspection and management mode.funcs- Enable function inspection and management. Defaults totrue.objects- Enable object inspection and management. Defaults totrue.permissions- Enable permission (ACL) inspection and management. Defaults tofalse.roles- Enable role inspection and management. Defaults tofalse.sensitive- Control sensitive values (e.g., passwords) in migration planning. AcceptsALLOWorDENY(default).tables- Enable table inspection and management. Defaults totrue.triggers- Enable trigger inspection and management. Defaults totrue.types- Enable type inspection and management. Defaults totrue.views- Enable view inspection and management. Defaults totrue.
-
format- A block defines the formatting configuration of the env per command (previously namedlog).migrateapply- Set custom formatting formigrate apply.diff- Set custom formatting formigrate diff.lint- Set custom formatting formigrate lint.status- Set custom formatting formigrate status.
schemainspect- Set custom formatting forschema inspect.apply- Set custom formatting forschema apply.diff- Set custom formatting forschema diff.
-
lint- A block defines the migration linting configuration of the env.format- Override the--formatflag by setting a custom logging formigrate lint(previously namedlog).latest- A number configures the--latestoption.git.base- A run analysis against the base Git branch.git.dir- A path to the repository working directory.review- The policy to use when deciding whether the user should be prompted to review and approve the changes. Currently works with declarative migrations and requires the user to log in. Supported options:ALWAYS- Always prompt the user to review and approve the changes.WARNING- Prompt if any diagnostics are found.ERROR- Prompt if any severe diagnostics (errors) are found. By default this will happen on destructive changes only.
-
diff- A block defines the schema diffing policy. -
data- A block defines the data synchronization configuration. See Data Configuration below. -
rollout- A block defines the deployment rollout strategy for multi-tenant environments.deployment- A reference to adeploymentblock that defines the rollout groups and execution order.vars- A map of variables to pass to the deployment block for group matching.
-
export- A block defines the export configuration for the env. See Exporters.schemainspect- Reference to an exporter foratlas schema inspect --export.
Multi Environment Example
Atlas adopts the for_each meta-argument that Terraform uses
for env blocks. Setting the for_each argument will compute an env block for each item in the provided value. Note
that for_each accepts a map or a set of strings.
- Versioned Migration
- Declarative Migration
env "prod" {
for_each = toset(data.sql.tenants.values)
url = urlsetpath(var.url, each.value)
migration {
dir = "file://migrations"
}
format {
migrate {
apply = format(
"{{ json . | json_merge %q }}",
jsonencode({
Tenant : each.value
})
)
}
}
}
env "prod" {
for_each = toset(data.sql.tenants.values)
url = urlsetpath(var.url, each.value)
src = "schema.hcl"
format {
schema {
apply = format(
"{{ json . | json_merge %q }}",
jsonencode({
Tenant : each.value
})
)
}
}
// Inject custom variables to the schema.hcl defined below.
tenant = each.value
}
variable "tenant" {
type = string
description = "The schema we operate on"
}
schema "tenant" {
name = var.tenant
}
table "users" {
schema = schema.tenant
// ...
}
Script Block
The script block defines where the Data Scripts for an environment reside:
env "prod" {
// ..
script {
// A single URL: a script file, or a directory of *.script.hcl files.
src = "file://scripts"
}
}
src takes one URL, not a list. Once defined, atlas script exec, query, loop, and
push pick up the source from the selected environment, so --file becomes optional:
atlas script exec --env prod --run archive_dormant
To push the source to the Atlas Registry and run it from there,
name the repository with a nested repo block:
env "prod" {
script {
src = "file://scripts"
repo {
name = "my-scripts"
backup = ["file://scripts-backup"]
}
}
}
script blocksThis env-level block is not the script block used inside a test block, which selects the
scripts a test case runs. That one takes a required list of sources plus vars, and it is never
fed by env.script.src: atlas script test always names its own files. See
Testing Data Scripts.
Attributes set on the env block that are not consumed by the environment itself are
forwarded to the scripts' variable blocks, and may reference the project's own
variables. Values passed with --var are also bound to matching variable blocks,
with the env attribute taking precedence when both set the same key:
env "prod" {
days = 30
script {
src = "file://scripts"
}
}
atlas script loop --env prod --run gdpr_purge --var days=90
Configure Schema Mode
Config files may declare schema.mode blocks to configure how schema inspection and management works.
By default, tables, views, triggers, functions, types, and objects are included in inspection and management.
Roles, users and permissions are excluded by default. To enable or disable specific resources, configure the mode
block within the schema block:
env "dev" {
url = "postgres://user:pass@localhost:5432/dev"
dev = "docker://postgres/15/dev"
schema {
src = "file://schema.hcl"
mode {
roles = true // Enable roles and users inspection. Defaults to false.
permissions = true // Enable permission inspection. Defaults to false.
sensitive = ALLOW // or DENY (default) - controls password handling.
}
}
}
Configure Migration Linting
Config files may declare lint blocks to configure how migration linting runs in a specific environment or globally.
lint {
destructive {
// By default, destructive changes cause migration linting to error
// on exit (code 1). Setting `error` to false disables this behavior.
error = false
}
// Custom logging can be enabled using the `format` attribute (previously named `log`).
format = <<EOS
{{- range $f := .Files }}
{{- json $f }}
{{- end }}
EOS
}
env "local" {
// Define a specific migration linting config for this environment.
// This block inherits and overrides all attributes of the global config.
lint {
latest = 1
}
}
env "ci" {
lint {
git {
base = "master"
// An optional attribute for setting the working
// directory of the git command (-C flag).
dir = "<path>"
}
}
}
Data Configuration Atlas Pro
The data block within an environment configures how Atlas synchronizes lookup table data defined in your schema.
This allows you to manage reference data (like country codes, currencies, or configuration values) declaratively
alongside your schema.
Configuration Options
env "dev" {
...
data {
// Required: The sync mode
mode = UPSERT
// Optional: Only include tables matching these patterns
include = ["countries", "currencies", "config_*"]
// Optional: Exclude tables matching these patterns
exclude = ["temp_*", "test_*"]
// Optional: Exclude columns from data diff comparison
skip_diff = ["*.updated_at", "*.created_at"]
// Optional: Emit explicit values for auto-increment/identity primary key columns
preserve_ids = true
// Required when working against a database connection (safety limit to avoid full table scans)
max_rows = 1000
}
}
Attributes
-
mode(required) - The synchronization mode:INSERT- Add new rows only, preserve all existing data.UPSERT- Insert new rows and update existing ones by primary key.SYNC- Full synchronization to exactly match desired state (inserts, updates, and deletes).
-
exclude- A list of glob patterns to exclude matching tables. Works similar to the standard--excludeflag in Atlas schema workflows. The pattern format depends on your URL scope: for database scope useschema.table, for schema scope usetabledirectly. -
include- A list of glob patterns to include only matching tables. Applied afterexclude. Works similar to the standard--includeflag in Atlas schema workflows. If not specified, all tables withdatablocks are included. -
skip_diff- A list of glob patterns specifying columns to exclude from data diff comparison. This is useful for columns with dynamic defaults (e.g.,now()) that evaluate to a different value each time the dev database is provisioned, causing falseUPDATEstatements. Patterns use dot-separated globs: for schema-scoped connections (URL targets a specific schema), usetable.column(e.g.,*.updated_at,users.created_at); for realm-scoped connections (URL targets an entire database), useschema.table.column(e.g.,*.*.updated_at,public.users.created_at). Standard glob characters (*,?,[...]) are supported. Only affectsUPSERTandSYNCmodes:INSERTmode does not generate updates, soskip_diffhas no effect. -
preserve_ids- Defaults tofalse. Whentrue, generatedINSERTstatements include the explicit values of auto-increment and identity primary-key columns instead of letting the database assign new values. See Preserving Explicit IDs for engine support and details. -
max_rows- Maximum number of rows to manage per table. Required when working against a database connection to avoid full table scans. This safety limit prevents accidentally processing large tables or unintended mass deletions.
Backup Repository Configuration Atlas Pro
Configure backup repositories for migration directories using the migration.repo.backup attribute:
env "prod" {
migration {
repo {
name = "app"
backup = [
"s3://my-atlas-backups/migrations?region=us-east-1",
]
}
}
}
Use the provider-specific URL examples for AWS S3, GCP, and Azure in Connect Migration Directories.
Configure Diff Policy
Config files may define diff blocks to configure how schema diffing runs in a specific environment or globally.
diff {
skip {
// By default, none of the changes are skipped.
drop_schema = true
drop_table = true
}
concurrent_index {
create = true
drop = true
}
}
env "local" {
// Define a specific schema diffing policy for this environment.
diff {
skip {
drop_schema = true
}
}
}
Example: PostgreSQL NOT NULL Policy Atlas Pro
The driver-specific diff "postgres" block configures how Atlas plans NOT NULL changes on
PostgreSQL. The not_null sub-block can generate a pre-migration check and plan the change to
avoid an ACCESS EXCLUSIVE lock for a full table scan:
diff "postgres" {
not_null {
// Generate an MF104 pre-migration check asserting the column has no NULLs before the file runs.
check = true
// Plan the NOT NULL change to avoid an ACCESS EXCLUSIVE lock for a full table scan.
lock_safe = true
}
}
| Attribute | Type | Effect |
|---|---|---|
check | bool | Generate an MF104 pre-migration check asserting the column has no NULLs before the migration file runs. |
lock_safe | bool | Plan the NOT NULL change to avoid an ACCESS EXCLUSIVE lock for a full table scan. Requires check. |
See the Safe NOT NULL Migrations on PostgreSQL guide for the exact SQL
Atlas emits on PostgreSQL 18 and below, the special cases, and how the plan clears the
PG303 lint check.