Automatic ClickHouse Schema Migrations with Atlas
ClickHouse, one of the prominent columnar databases, is designed for real-time analytics, providing exceptional speed and efficiency in handling large datasets, but managing its schema can be a puzzle.
If your schema contains a handful of tables that rarely change, you’re probably not going to feel much of this pain. But for mission-critical applications, managing complex and interconnected schemas quickly without breaking things becomes difficult.
Enter: Atlas
Atlas helps developers manage their database schema as code - abstracting away the intricacies of database schema management. With Atlas, users provide the desired state of the database schema and Atlas automatically plans the required migrations.
In this guide, we will set up Atlas for declarative and versioned ClickHouse schema migration and walk through both workflows.
Prerequisites
- Docker
- Atlas installed on your machine:
- macOS + Linux
- Homebrew
- Docker
- Windows
- CI
- Manual Installation
To download and install the latest release of the Atlas CLI, simply run the following in your terminal:
curl -sSf https://atlasgo.sh | sh
Get the latest release with Homebrew:
brew install ariga/tap/atlas
To pull the Atlas image and run it as a Docker container:
docker pull arigaio/atlas
docker run --rm arigaio/atlas --help
If the container needs access to the host network or a local directory, use the --net=host flag and mount the desired
directory:
docker run --rm --net=host \
-v $(pwd)/migrations:/migrations \
arigaio/atlas migrate apply \
--url "mysql://root:pass@:3306/test"
Download the latest release and move the atlas binary to a file location on your system PATH.
GitHub Actions
Use the setup-atlas action to install Atlas in your GitHub Actions workflow:
- uses: ariga/setup-atlas@v0
with:
cloud-token: ${{ secrets.ATLAS_CLOUD_TOKEN }}
Other CI Platforms
For other CI/CD platforms, use the installation script. See the CI/CD integrations for more details.
Logging in to Atlas
ClickHouse is only available on the Pro plan or during a Trial. Upgrade your plan to get started.
To use ClickHouse with Atlas, you'll need to log in to Atlas. If it's your first time, you will be prompted to create both an account and a workspace ("organization"):
- Via Web
- Via Token
- Via Environment Variable
atlas login
atlas login --token "ATLAS_TOKEN"
ATLAS_TOKEN="ATLAS_TOKEN" atlas login
Getting Started
If you already have a database in ClickHouse Cloud, follow our ClickHouse Cloud guide for setting up the connection and a dev database. You can then go straight to the Inspecting our Database section, using the URL from Step 3 for this guide.
Let's start by spinning up a local database using Docker:
docker run --rm -d --name atlas-demo -e CLICKHOUSE_DB=demo -e CLICKHOUSE_PASSWORD=pass -p 9000:9000 clickhouse/clickhouse-server:latest
For this example, we will begin with a minimal database containing a users table with id as the primary key.
CREATE TABLE `users` (
`id` UInt64,
`name` String NOT NULL,
PRIMARY KEY (`id`)
) ENGINE = MergeTree() ORDER BY id;
To create this in our local database, run the following command:
docker exec -it atlas-demo clickhouse-client --query 'CREATE TABLE demo.users (id UInt64, name String NOT NULL, PRIMARY KEY (id)) ENGINE = MergeTree() ORDER BY id'
Inspecting our Database
The atlas schema inspect command takes a a URL and outputs its schema definition. In this guide, we
will demonstrate this flow using both the Atlas DDL (default) and SQL formats for the output.
- Atlas DDL (HCL)
- SQL
To inspect our locally-running ClickHouse instance, use the -u flag and write the output to a file named schema.hcl:
atlas schema inspect -u "clickhouse://default:pass@localhost:9000/demo" > schema.hcl
Open the schema.hcl file to view the Atlas schema that describes our database.
table "users" {
schema = schema.demo
engine = MergeTree
column "id" {
null = false
type = UInt64
}
column "name" {
null = false
type = String
}
primary_key {
columns = [column.id]
}
}
schema "demo" {
engine = sql("Memory")
}
This first block represents a table resource with id and name columns.
The schema field references the demo schema that is defined in the block below. The primary_key
sub-block establishes the id column as the primary key for the table.
Atlas mimics the syntax of the database that the user is working against. In this case, the type for the id column
is UInt64, and the name column's is String.
To inspect our ClickHouse instance, pass the URL using the -u flag and write the output to a file named schema.sql:
atlas schema inspect -u "clickhouse://default:pass@localhost:9000/demo" --format '{{ sql . }}' > schema.sql
Open the schema.sql file to view the inspected SQL schema that describes our database.
CREATE TABLE `users` (
`id` UInt64,
`name` String)
ENGINE = MergeTree
PRIMARY KEY (`id`)
SETTINGS index_granularity = 8192;
To learn more about using the atlas schema inspect command, such as inspecting specific schemas,
handling multiple schemas concurrently, excluding tables, and more, refer to our documentation
here.
To generate a visual representation of our schema as an Entity Relationship Diagram (ERD) on Atlas Cloud,
we can add the -w flag to the inspect command:
atlas schema inspect -u "clickhouse://default:pass@localhost:9000/demo" -w
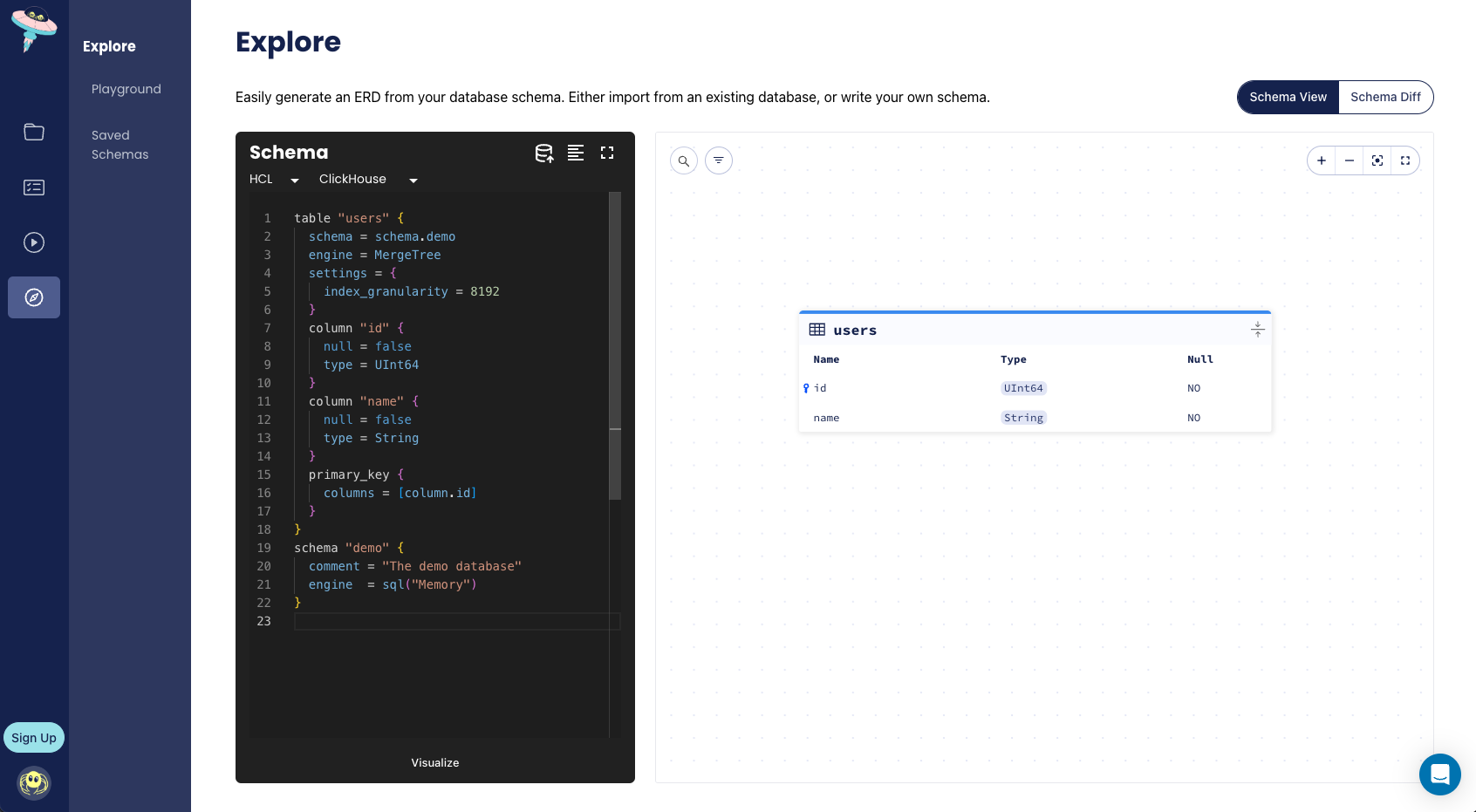
Declarative Migrations
Using the declarative approach, users define the desired state of their database schema as code. Atlas then inspects the target database's current state and calculates an execution plan to reach the desired state.
Let's see this in action.
We will start off by making a change to our schema file by adding a repos table:
- Atlas DDL (HCL)
- SQL
table "users" {
schema = schema.demo
engine = MergeTree
column "id" {
null = false
type = UInt64
}
column "name" {
null = false
type = String
}
primary_key {
columns = [column.id]
}
}
table "repos" {
schema = schema.demo
engine = MergeTree
column "id" {
type = UInt64
null = false
}
column "name" {
type = String
null = false
}
column "owner_id" {
type = Bigint
null = false
}
primary_key {
columns = [column.id]
}
}
schema "demo" {
engine = sql("Memory")
}
-- Create "users" table
CREATE TABLE `users` (
`id` UInt64,
`name` String)
ENGINE = MergeTree
PRIMARY KEY (`id`)
SETTINGS index_granularity = 8192;
-- Create "repos" table
CREATE TABLE `repos` (
`id` UInt64,
`name` String,
`owner_id` Int64)
ENGINE = MergeTree
PRIMARY KEY (`id`)
SETTINGS index_granularity = 8192;
Now that our desired state has changed, we run atlas schema apply to get Atlas to plan the migration
that will apply these changes to our database:
- Atlas DDL (HCL)
- SQL
atlas schema apply \
-u "clickhouse://default:pass@localhost:9000/demo" \
--to file://schema.hcl \
--dev-url "docker://clickhouse/23.11/demo"
atlas schema apply \
-u "clickhouse://default:pass@localhost:9000/demo" \
--to file://schema.sql \
--dev-url "docker://clickhouse/23.11/demo"
Apply the changes, and that's it! You have successfully run a declarative migration.
For a more detailed description of the atlas schema apply command, refer to our documentation
here.
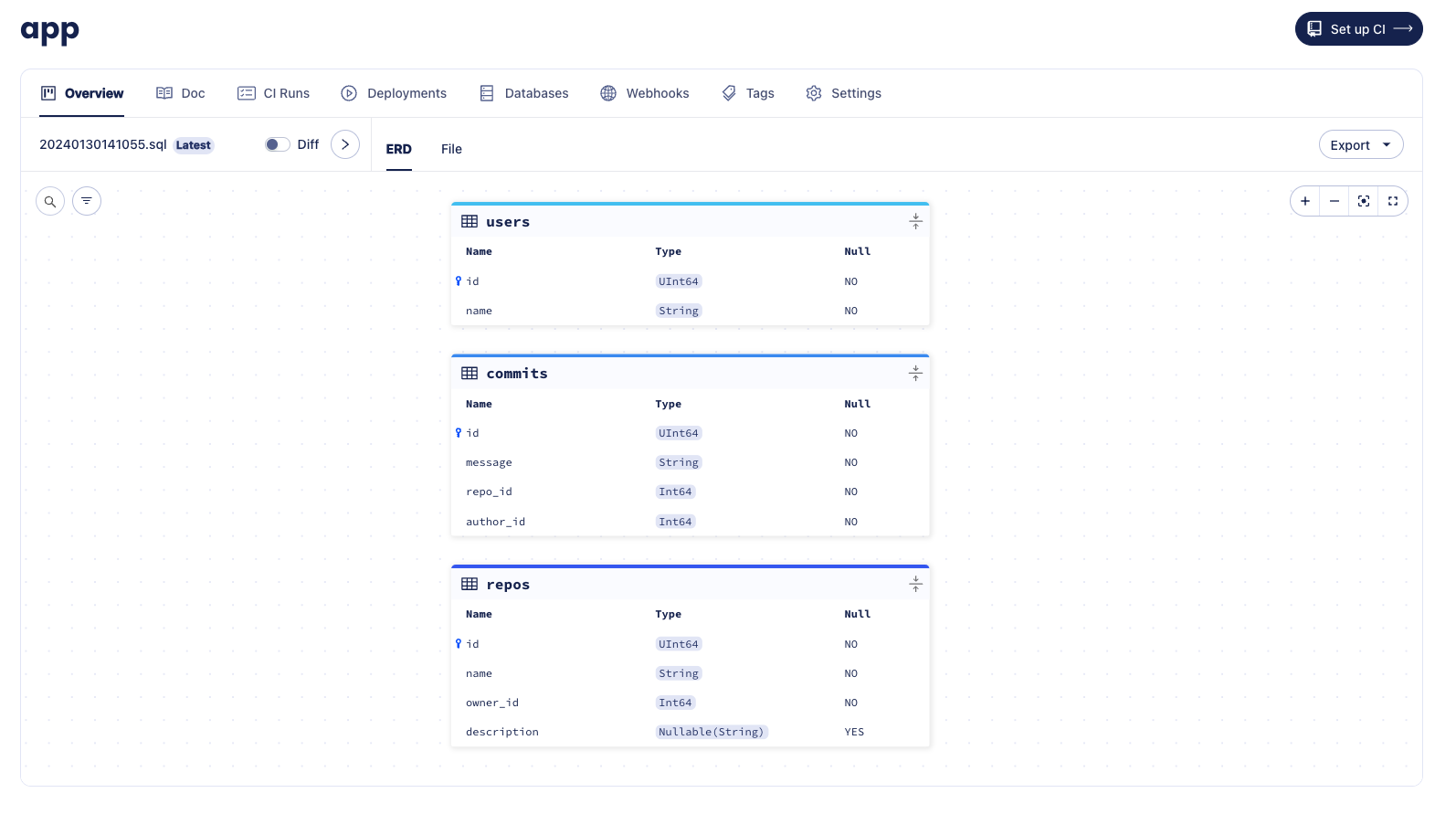
To ensure that the changes have been made to the schema, let's run the inspect command with the -w flag once more
and view the ERD:
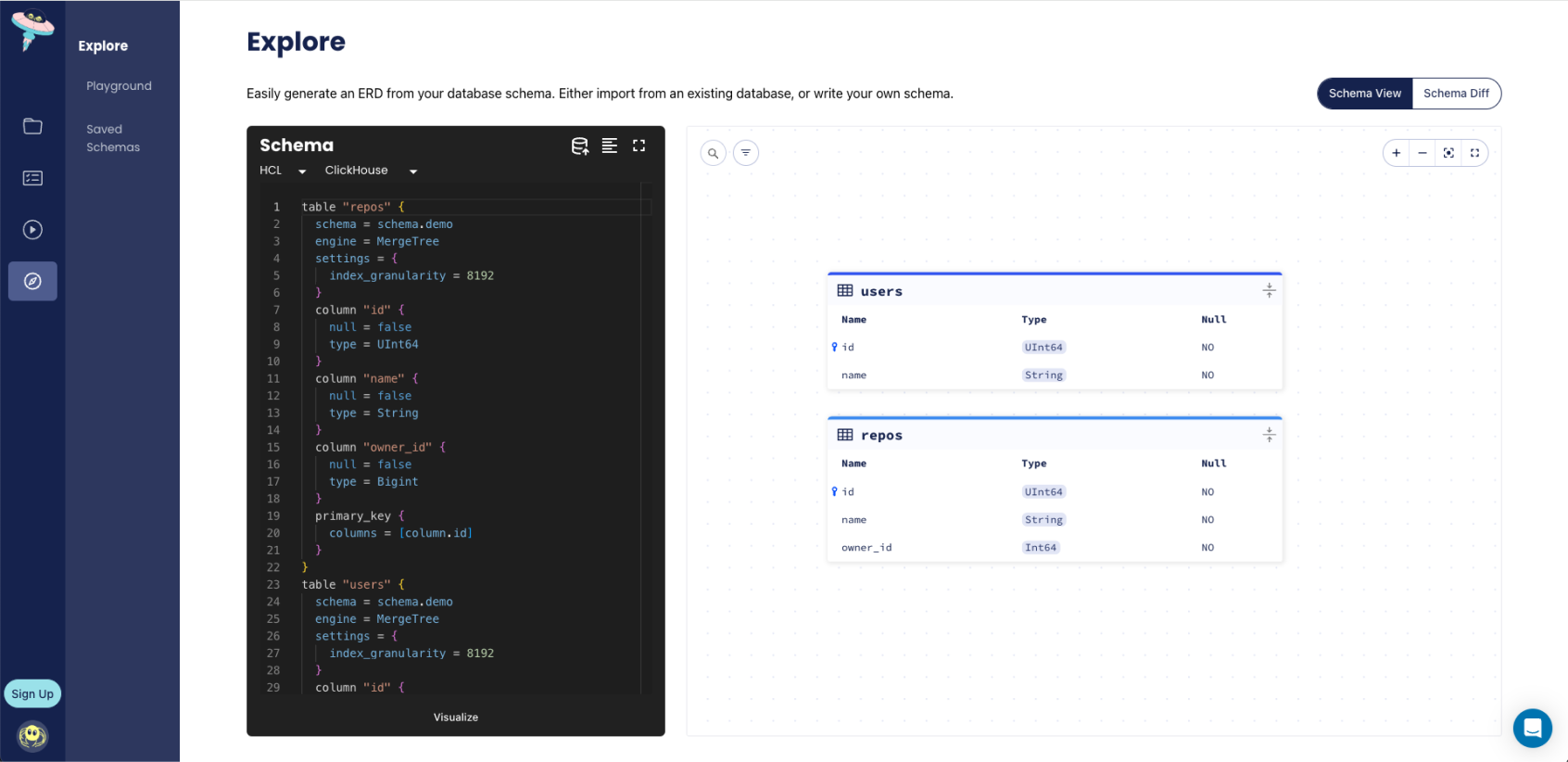
Versioned Migrations
Alternatively, there is the versioned migrations workflow, sometimes called change-based migrations, where each migration is saved in source control to be evaluated during code-review and applied later. Users still benefit from Atlas intelligently planning migrations for them, but they are not automatically applied.
Creating the first migration
When using the versioned migration workflow, our database state is managed by a migration directory. The migration directory holds all of the migration files created by Atlas, and the sum of all files in lexicographical order represents the current state of the database.
To create our first migration file, we will run the atlas migrate diff command with the necessary parameters:
--dir- The URL to the migration directory,file://migrationsby default.--to- The URL of the desired state. A state can be specified using a database URL, an HCL or SQL schema definition, or another migration directory.--dev-url- A URL to a Dev Database that will be used to compute the diff.
- Atlas DDL (HCL)
- SQL
atlas migrate diff initial \
--to file://schema.hcl \
--dev-url "docker://clickhouse/23.11/dev"
atlas migrate diff initial \
--to file://schema.sql \
--dev-url "docker://clickhouse/23.11/dev"
Run ls migrations, and you'll notice that Atlas has automatically created a migration directory for us, as well as
two files:
- 20240130122951_initial.sql
- atlas.sum
-- Create "users" table
CREATE TABLE `users` (
`id` UInt64,
`name` String)
ENGINE = MergeTree
PRIMARY KEY (`id`)
SETTINGS index_granularity = 8192;
-- Create "repos" table
CREATE TABLE `repos` (
`id` UInt64,
`name` String,
`owner_id` Int64)
ENGINE = MergeTree
PRIMARY KEY (`id`)
SETTINGS index_granularity = 8192;
h1:NrYfakYn4W3xiS9VqcP98sqvgLUPn9pJpxFndh1GWsQ=
20240130122951.sql h1:R+eBw2nOk2+VLBvJ/dn49OphxzfxoWEBUxAy4Zp3VAE=
The migration file represents the current state of our database, and the sum file is used by Atlas to maintain the integrity of the migration directory.
Pushing migration directories to Atlas
Now that we have our first migration, we can push the migration directory to Atlas Cloud, much like how Docker images are pushed to Docker Hub.
Let's name our new migration project app and run atlas migrate push:
atlas migrate push app \
--dev-url "docker://clickhouse/23.11"
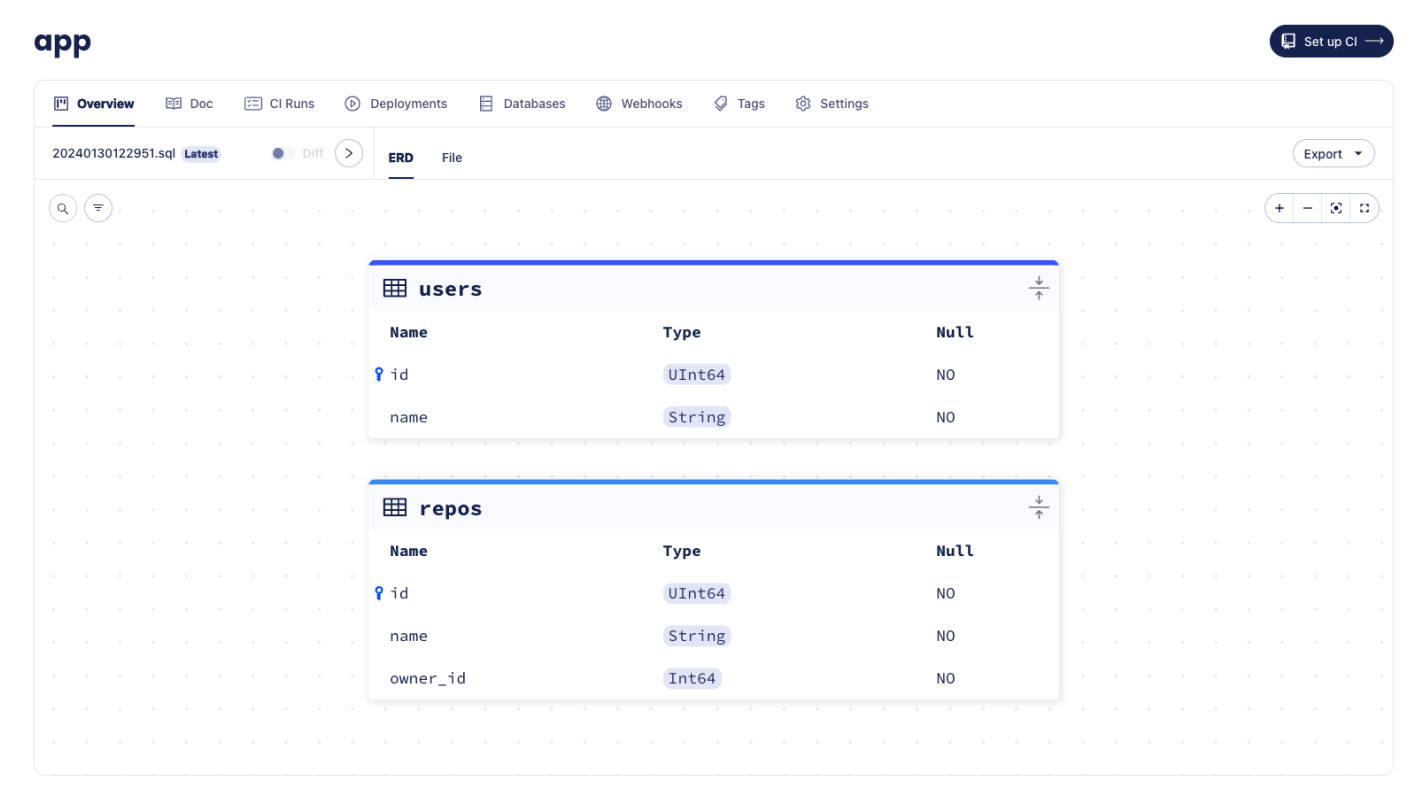
Migration Directory created with atlas migrate push
Once the migration directory is pushed, Atlas prints a URL to the created directory, similar to the once shown in the image above.
Applying migrations
Once our app migration directory has been pushed, we can apply it to a database from any CD platform without
necessarily having our directory there.
We'll create a simple Atlas configuration file (atlas.hcl) to store the settings for our local environment:
# The "dev" environment represents our local testings.
env "local" {
url = "clickhouse://localhost:9000/example"
migration {
dir = "atlas://app"
}
}
Run atlas migrate apply with the --env flag to instruct Atlas to select the environment configuration from the atlas.hcl file:
atlas migrate apply --env local
Boom! After applying the migration, you should receive a link to the deployment and the database where the migration was applied. Here's an example of what it should look like:
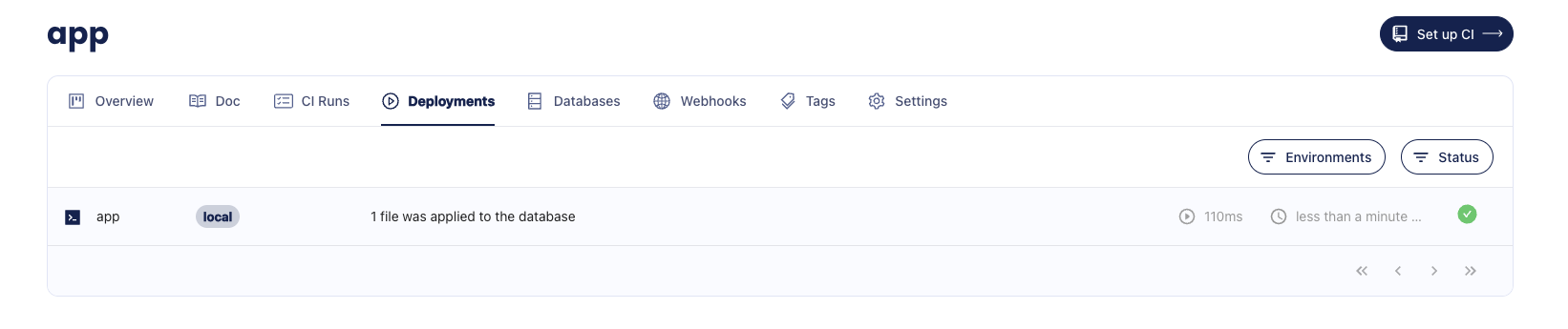
Migration deployment report created with atlas migrate apply
Generating another migration
After applying the first migration, it's time to update our schema definition file and tell Atlas to generate another migration.
Let's make two changes to our schema:
- Add a new
descriptioncolumn to our repos table - Add a new
commitstable
- Atlas DDL (HCL)
- SQL
table "users" {
schema = schema.demo
engine = MergeTree
column "id" {
null = false
type = UInt64
}
column "name" {
null = false
type = String
}
primary_key {
columns = [column.id]
}
}
table "repos" {
schema = schema.demo
engine = MergeTree
column "id" {
type = UInt64
null = false
}
column "name" {
type = String
null = false
}
column "description" {
type = sql("Nullable(String)")
null = true
}
column "owner_id" {
type = Bigint
null = false
}
primary_key {
columns = [column.id]
}
}
table "commits" {
schema = schema.demo
engine = MergeTree
column "id" {
type = UInt64
null = false
}
column "message" {
type = String
null = false
}
column "repo_id" {
type = Bigint
null = false
}
column "author_id" {
type = Bigint
null = false
}
primary_key {
columns = [column.id]
}
}
schema "demo" {
engine = sql("Memory")
}
CREATE TABLE `users` (
`id` UInt64,
`name` String NOT NULL
) ENGINE = MergeTree
PRIMARY KEY (`id`)
SETTINGS index_granularity = 8192;
CREATE TABLE `repos` (
`id` UInt64,
`name` String NOT NULL,
`description` String NULL,
`owner_id` Bigint NOT NULL
) ENGINE = MergeTree
PRIMARY KEY (`id`)
SETTINGS index_granularity = 8192;;
CREATE TABLE `commits` (
`id` UInt64,
`message` String NOT NULL,
`repo_id` Bigint NOT NULL,
`author_id` Bigint NOT NULL,
) ENGINE = MergeTree
PRIMARY KEY (`id`)
SETTINGS index_granularity = 8192;
Next, run the atlas migrate diff command again:
- Atlas DDL (HCL)
- SQL
atlas migrate diff add_commits \
--to file://schema.hcl \
--dev-url "docker://clickhouse/23.11/dev"
atlas migrate diff add_commits \
--to file://schema.sql \
--dev-url "docker://clickhouse/23.11/dev"
Run ls migrations, and you'll notice that a new migration file has been generated.
ALTER TABLE `repos` ADD COLUMN `description` Nullable(String);
-- Create "commits" table
CREATE TABLE `commits` (
`id` UInt64,
`message` String,
`repo_id` Int64,
`author_id` Int64
) ENGINE = MergeTree
PRIMARY KEY (`id`)
SETTINGS index_granularity = 8192;
If you run atlas migrate push again, you can observe the new file on the migration directory page.
atlas migrate push app \
--dev-url "docker://clickhouse/23.11/dev"
Migration Directory created with atlas migrate push
Finally, run atlas migrate apply again to apply the new migration to the database:
atlas migrate apply --env local
Video Tutorial
Check out the video below for a basic demonstration of using Atlas in CI/CD to manage your ClickHouse database using the declarative workflow.
GitHub Repository
We also put together a GitHub repository with more workflow setup instructions and example files to help you get started using Atlas.
Next Steps
In this guide we learned about the declarative and versioned workflows, and how to use Atlas to generate migrations, push them to an Atlas workspace, and apply them to ClickHouse databases.
Next steps:
- Read the full docs to learn HCL schema syntax and specific ClickHouse column types
- Learn how to set up CI for your migration directory
- Deploy schema changes with Terraform or Kubernetes
- Learn about modern CI/CD principles for databases
For more in-depth guides, check out the other pages in this section or visit our Docs section.
Have questions? Feedback? Find our team on our Discord server.